
技术篇:Python爬虫介绍

首次看本专栏文章的小伙建议先看一下介绍专栏结构的这篇文章: 专栏文章分类及各类内容简介。
爬虫是一段自动抓取互联网信息的程序。互联网由各种各样的网页构成,每一个网页都对应对应着url,url页面上又有很多指向其他的页面url,url之间相互的指向关系形成一个网状,这就是互联网。正常情况下,我们使用人工的方式从互联网上获取我们所需要的、有价值的、感兴趣的东西,这种方式的特点就是覆盖面比较小。爬虫方法根据设定的主题和感兴趣的目标可以自动的从互联网上获取我们所需要的数据,爬虫从一个url出发,访问它所关联的所有url,并且从每一个页面上获取提取所需要有价值的数据。爬虫就是自动访问互联网并且提取数据的程序。
该篇文章与专栏主题的关系
在机器学习、数据挖掘领域,爬虫技术主要用于收集数据。爬虫获取的数据可以认为是“未经加工的数据集”,在对这些“生数据”进行处理后,便可以获得用来直接进行训练的“训练集”、进行算法性能测试的“测试集”等。所以了解爬虫技术、学会使用爬虫技术爬取数据也是机器学习、数据挖掘任何子领域学习者及从业者必须掌握的一项基本技能,不仅仅局限于推荐系统领域。
爬虫技术架构
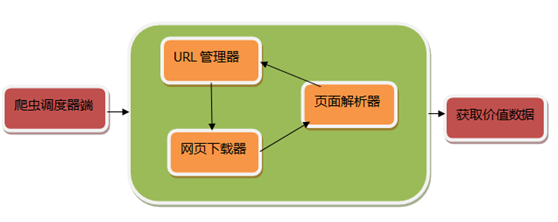
首先由爬虫调度端来启动、停止、监视爬虫情况,接下来进入循环爬虫过程。循环爬虫的过程主要是URL管理器、页面下载器、网页下载器三者进行信息交互的过程。其中,URL管理器部分主要负责管理将要爬取的URL;页面下载器主要负责将互联网上URL对应的网页下载到本地;网页解析器则通过网页解释器解析、获取你想要的、感兴趣的内容。在后面的内容里会更加详细地介绍这三个部分。
下图为爬虫的架构图:

爬虫过程的顺序图
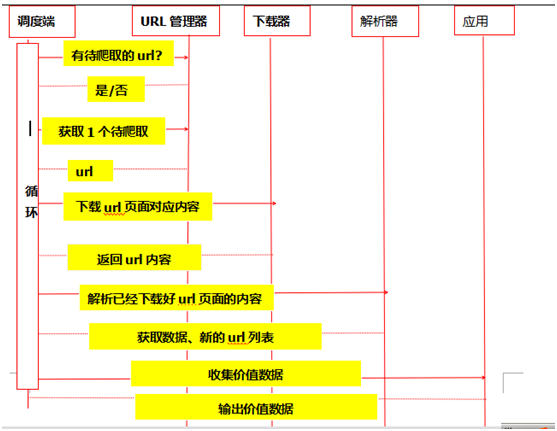
爬虫过程的时序图可以清晰、直观的展示整个爬虫的过程。具体过程概述如下:首先调度端启动爬虫,询问url管理器是否有要爬取的url。url管理器将要爬取的url返还给调度端,调度端根据获取的url,利用网页下载器下载url对应的页面内容。网页下载器将下载好的内容发给页面解析器来解析,返回解析好的内容和新的url列表,获取所感兴趣的有价值的数据。根据时序图可以直观了解爬虫过程,如下图所示:

爬虫各部分的介绍
1. 爬虫调度器
爬虫调度器负责启动、停止、监视爬虫的情况,是整个爬虫过程的入口
2.URL管理器
URL管理器是用来管理待爬取的URL集合和已爬取的URL集合,使用URL管理器的原因是为了防止重复抓取、循环抓取:有很多网页中可能有相同的url网址,因此如果没有url管理器,可能会出现重复爬取某页面的情况,降低效率;另外一种情况是爬取两个互相关联的页面A、B时,爬取页面A将获得页面B的url,接着爬取页面B又获得了页面A的url这是就发生了循环爬取。而url管理器则可以很好地解决上述两种情况。
那么url管理器主要完成了哪些功能呢?首先url管理器添加了新的url到待爬取集合中,判断了待添加的url是否在容器中、是否有待爬取的url,并且获取待爬取的url,将url从待爬取的url集合移动到已爬取的url集合。下图可以清晰直观地看到url管理器完成的功能:


3. 网页下载器
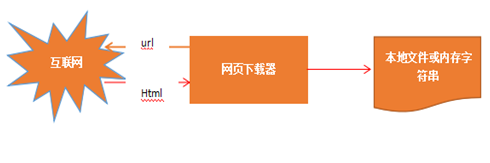
将互联网上url对应的页面下载到本地的工具。实现的过程如下:下载器将接收到的url传给互联网,互联网返回html文件给下载器,下载器将其保存到本地。实现过程如下图所示:

4. 页面解析器
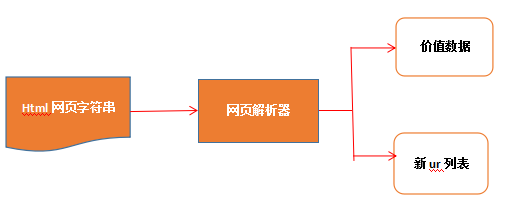
页面解析器主要完成的是从获取的html网页字符串中取得有价值的感兴趣的数据和新的url列表。实现过程如下图所示:

使用Python语言实现爬虫的实例代码
下面是爬取百度百科python词条相关的1000个页面的数据的示例程序(完整代码请见: 本文爬虫代码):
1.调度端主程序(spider_main.py)
# -*- coding: UTF-8 -*-
import url_manager,html_downloader,html_outputer,html_parser
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self,root_url):
self.urls.add_new_url(root_url)
count = 1
while self.urls.has_new_url():
new_url = self.urls.get_new_url()
print("craw %d:%s"%(count, new_url))
html_cont = self.downloader.downloder(new_url)
new_urls, new_data = self.parser.parser(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
try:
if count == 1000:
break
count += 1
except:
print("failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
2.url管理器(url_manager.py)
# -*- coding: UTF-8 -*-
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls == None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) !=0
3.下载器(html_downloader.py)
# -*- coding: UTF-8 -*-
import urllib2
class HtmlDownloader(object):
def downloder(self,url):
if url is None:
return None
response = urllib2.urlopen(url)
if response.getcode() != 200:
return None
return response.read()4.解析器(html_paser.py)
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import re,urlparse
class HtmlParser(object):
def _get_new_urls(self,page_url, soup):
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_datas(self,page_url, soup):
new_datas = {}
#url
new_datas['url'] = page_url
#<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
title_node = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
#print(title_node)
new_datas['title'] = title_node.get_text()
#<div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find('div',class_="lemma-summary")
if summary_node is None:
return
# print(summary_node)
new_datas['summary'] = summary_node.get_text()
return new_datas
def parser(self,page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_datas(page_url, soup)
return new_urls,new_data
5.输出(html_outputer.py)
# -*- coding: UTF-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data):
if data is None or len(data) == 0:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html','w')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>%s</td>" % data['title'].encode('utf-8'))
fout.write("<td>%s</td>" % data['summary'].encode('utf-8'))
fout.write("<tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()6.爬取结果截图:


参考资料
- Python开发简单爬虫_python爬虫入门教程_python爬虫视频教程-慕课网
- 史上最全Python数据分析学习路径图 - OPEN 开发经验库
文章被以下专栏收录
