图的广度优先搜索


本节课是小密圈《进击的Java新人》第二十一周第二节课。这节课我们来看一下图的遍历的问题。
图的遍历问题,就是指依照连通性,把图中所有的点都访问一遍,而且每个节点只访问一次,不会出现重复访问。
图的程序表达
在这之前,我们得先把图在程序中创建出来。通常,我们都是从控制台上读入数据,建立一个图。仍然以上节课的图为例:
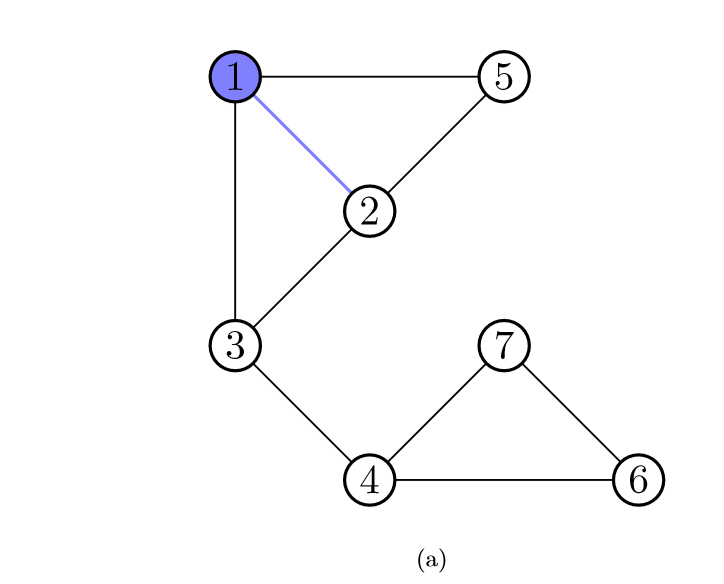

我们可以用边来描述这个图,先输入两个数字,第一个数字 v 代表多少个节点,第二个数字 e 代表多少个边。然后接下来的 e 行,每一行都是一对数字,分别代表每条边的两个端点。例如,上图就可以这样输入:
7 9
1 2
1 3
1 5
2 5
2 3
3 4
4 6
4 7
6 7第一行的7,9,代表了7个顶点,9条边,然后下面的9行,分别描述了每条边的端点。那我们就写一个与此相对应的程序,来创建一个图:
public class GraphDef {
public static void main(String[] args) throws IOException {
Scanner cin = new Scanner(System.in);
int v = cin.nextInt();
int e = cin.nextInt();
Graph g = new Graph(v, e);
for (int i = 0; i < e; i++) {
int a = cin.nextInt();
int b = cin.nextInt();
g.addEdge(a, b);
}
}
}
class Graph {
int v;
int e;
ListHead[] vertex;
public Graph(int v, int e) {
this.v = v;
this.e = e;
vertex = new ListHead[v + 1];
for (int i = 1; i <= v; i++) {
vertex[i] = new ListHead(i);
}
}
public void addEdge(int a, int b) {
vertex[a].linkTo(b);
vertex[b].linkTo(a);
}
}
class AdjacentListNode {
public int nodeIndex;
public int info;
public AdjacentListNode nextArc;
public AdjacentListNode(int nodeIndex) {
this.nodeIndex = nodeIndex;
nextArc = null;
}
}
class ListHead {
int data;
AdjacentListNode firstArc;
public boolean visited;
public ListHead(int data) {
this.data = data;
visited = false;
}
public void linkTo(int end) {
if (firstArc == null) {
firstArc = new AdjacentListNode(end);
return;
}
AdjacentListNode n = firstArc;
while (n.nextArc != null) {
n = n.nextArc;
}
n.nextArc = new AdjacentListNode(end);
}
}
我们通过运行这个程序,并且向控制台上输入上面的图的信息就可以创建一个无向图了。
广度优先搜索
给定图 G 和一个特定的源顶点 s,搜索算法会系统地搜索 G 中的边,用以发现可以从 s 到达的所有顶点,并计算 s 到所有这些可达顶点之间的距离。
为了记录搜索的轨迹,我们先来定义一下顶点分类。在算法执行的过程中,顶点可以分为以下三类,为了方便描述,我们给这三类结点都标上颜色。第一类是尚未访问过的结点,记他们的颜色为白色,第二类是已经访问过,但却没有扩展完的结点,记这类结点的颜色为灰色,第三类是已经访问过,并且已经全部扩展完的结点,记他们的颜色为黑色。
在算法开始之前,所有的顶点都是白色的。当某一个白色结点被搜索以后,就把它的颜色改为灰色,以表示已经该结点已经被发现,但尚未进行下一步扩展。然后再从灰色结点的集合中找到最早被发现的结点,记为 n,所有从 n 能直接到达的白色结点都是下一次扩展时要改为灰色的结点,当这些结点全部变为灰色以后,就可以把 n 的颜色改为黑色,表示 n 是一个已经全部扩展完了的结点。
从灰色结点集合中找到最早被置为灰色的结点并将其改为黑色这个操作,是典型的先进先出,所以可以使用队列来存储灰色结点集合。而一个结是否被发现,也就是区分一个结点是白还是非白只需要一个布尔型的变量(上文的程序中ListHead中的visited变量)就可以了。将上述文字描述的算法使用代码表示,就如下所示:
public class GraphDef {
public static void main(String[] args) throws IOException {
/*create graph, 略去*/
g.breadthFirstSearch();
}
}
class Graph {
public void breadthFirstSearch() {
ArrayQueue<ListHead> q = new ArrayQueue<>(v);
q.add(vertex[1]);
vertex[1].visited = true;
while (!q.isEmpty()) {
ListHead tmp = q.remove(0);
System.out.println(tmp.data);
AdjacentListNode n = tmp.firstArc;
while (n != null) {
tmp = vertex[n.nodeIndex];
if (!tmp.visited) {
q.add(tmp);
tmp.visited = true;
}
n = n.nextArc;
}
}
}
}
可见这种搜索算法的特点就是将已发现和未发现顶点之间的边界,沿其广度方向向外扩展,也就是说,算法首先会找到和 s 距离为 k 的所有顶点,然后才会找到和 s 距离为 k+1 的其他顶点。所以这种搜索算法才被称为广度优先搜索。
对于本节中所示的无向图,如果使用几幅图还表示它的广度优先搜索,就是这样的:


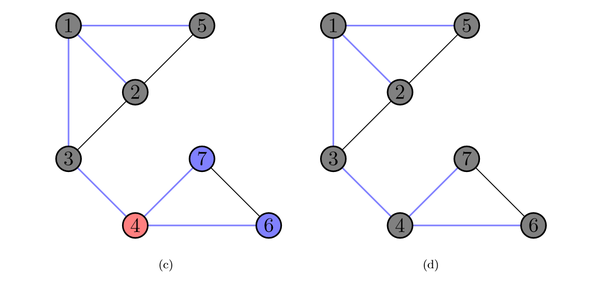

图中红色结点代表从队列中取出待扩展的结点,蓝色结点代表目前在队列中的结点,灰色结点代表已经访问过的结点。BFS 的每次扩展都会使离初始结点更远一层的结点被扩展进队。也就是说第1扩 展,会使得与初始结点距离为1的结点进队,而第2次扩展就会使与初始结点距离为2的结点进队,依次类推。
好了。今天就到这里了。
作业:
今天我的例子程序是使用邻接矩阵创建图的,请使用邻接表表示,并完成邻接表的广度优先遍历。
上一节课: 图算法:图的表达
下一节课: 习题课:八数码问题(上)
目录: 课程目录
文章被以下专栏收录
