首发于 爬虫之从入门到精通
切换模式
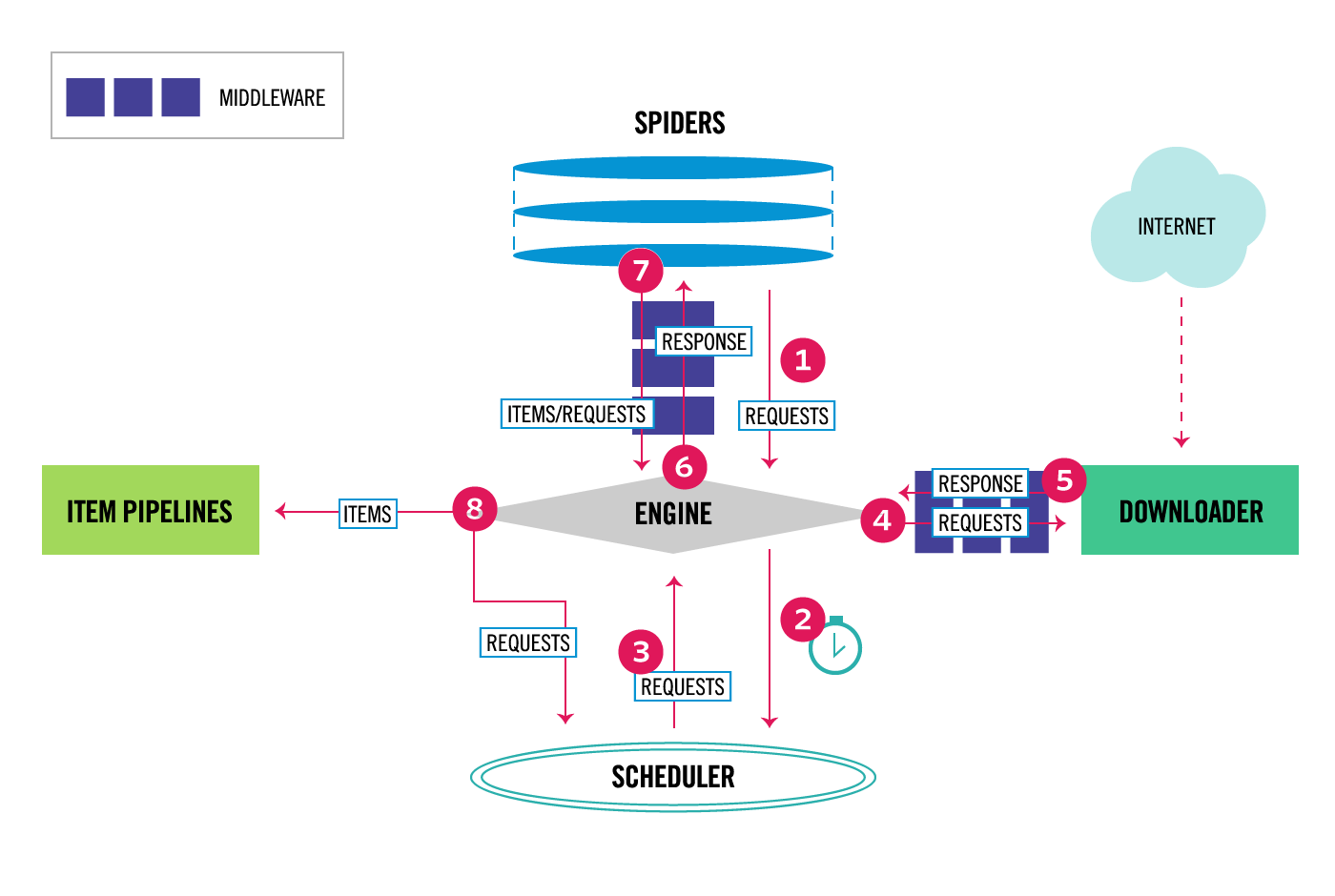
爬虫从入门到精通系统教程---目录

写bug的高师傅
准备写一个爬虫从入门到精通的教程,在这边先立个目录把,好给自己一些动力
- 爬虫的介绍
- 什么是爬虫
- 爬虫能干什么
- HTTP协议的讲解
- 爬虫的原理
- 爬虫环境的搭建
- IDE
- 各种包的安装
- 爬虫之网页下载
- 如何抓包
- 如何用程序模拟请求
- 爬虫之解析 正则表达式的基本使用 XPATH的基本使用
- CSS的基本使用
- headers的详细讲解
- Accept
User-Agent
- Referer
Cookie If-modified-since
- 爬虫之存储
- mongodb的基本使用
- 爬虫之异步加载
- 异步加载网页的抓包
- 模拟发送
- 爬虫之多线程
- 如何让爬虫更快
- scrapy的基本介绍
- 如何爬取大型网站
- scrapy的介绍
- scrapy的正确编写方式
- scrapy之下载中间件
- 各种下载中间件的使用
- 如何编写自己的下载中间件
- scrapy之技巧
- 如何调试scrapy
- form response
- cookie
- scrapy之分布式
- 爬虫总结及反爬技巧
欢迎关注本人的微信公众号获取更多Python爬虫相关的内容
(可以直接搜索「Python爬虫分享」)
编辑于 2018-01-03 09:47
Python
爬虫 (计算机网络)
文章被以下专栏收录
