广度优先搜索
详细内容
简介
广度优先算法,又称广度优先搜索算法,是最简便的图的算法之一,其特点是:在扫描数据空间时,每个点以最短路径生成广度优先生成树。广度优先搜索这种算法遍历整个图的所有节点并记录,直至找到所需结果为止,是一种盲目算法,但它还有一个非常重要的特性一最佳解,即当所有的边长相等,它就是最佳解,若在距离聚类算法中,应用广度优先搜索此特性去搜寻数据对象的同类,则可以有效地提高聚类速度。[1]
此外,可以把网格单元作为点来处理,利用广度优先搜索某网格的直接网格邻居单元邻居和间接网格邻居单元,以类似于树的层次迅速遍历整个网格空间,对符合条件的所有找到的邻居合并,从而将显著网格单元进行连通并聚类。同时设置类门限,归类时做出正确判断,提高聚类精度。[2]
主要过程
(1)将图中所有结点储存在队列中;
(2)从队列取出第一个结点,从此结点出发,访其未访问的所有邻接点,并将此结点从队列中删除;
(3)对所有邻接点重复步骤(2),直至队列为空。
编号方案
广度优先搜索编号即分层编号,是按照节点。支路及分支线距离根节点的远近,将网络元件划分为不同层次。然后根据层次遍历树的访问顺序,来给各支路和节点编号。广度优先搜索方案分为基于支路分层法和分支线分层法
分支线分层法编号方案
按照分支线距离根节点的远近,对分支线进行分层。即按照从分支线的末端到源节点所经历的分支数目对分支线进行分层从配电网选出一条带多条分支线路的主馈线。在分支线之下又分出子分支线,子分支线又可能再分出子分支线可以对节点编号采用规定方法:(1)分支线按所在的层次大小编号,主馈线的层次为1,其子分支线的层次为2,子分支线之下再分出子分支线的层次为3,以此类推。(2)同一层上的各分支线按宽度优先搜索进行顺序编号。(3)用一个标量Ⅳ=(a,b,C)给每个节点编号,a是节点分支线所在层次。b是该分支线在a层的次序。c是节点在分支线上的次序,节点表示第a条层次为b的分支线上的第C个节点。(4)源节点编号为~=(1,1,0)。
基于分支线分层法广度优先搜索编号方案分析
(1)节点编号复杂,对于分支线所在层次序以及该分支线在Ⅱ层的次序b的确定均需要根据其他分支线在a层的次序才能予以确定,尤其对于同一节点具有多条分支线,难以确定该分支线在层的次序6。(2)节点编号无法直观反应其拓扑结构,即无法根据节点编号构建拓扑结构,如Ni=(2,3、4)节点编号虽然知道该节点处于第2层次的第3条分支线上的第4个节点。但是却并不知道该节点所在分支线具体连接在哪4-节点上(3)用3类数字进行节点编号,计算机需要用三维数组来储存编号,占用内存大,降低计算速度。
算法
简化算法
基于广度优先算法的简化算法(v-bfs算法)
该算法运用图的广度优先搜索算法(BFS)来求解简化轨迹大小Tsim最小值问题,称该算法为V-bfs:算法,构造步骤如下:
(1)图的构造。构造一个图称为Ge(V,E),V表示点的集合,E表示边的集合。对任意的Pi点(1≤i<j≤n),对任意的位置点P和P(1≤i<j≤n),如果 (PiPj)≤
u,则边(Pi,pj)
E。
(2)寻找最短路径。在图Ge(V,E),中用广度优先索算法(BFS)寻找一条从P1到Pn的最短路径。
(3)找到图的简化轨迹。根据第(2)步的路径关系到一条简化轨迹。
优化算法
优化算法的目的是为了降低算法的时间复杂度,在提出优化算法之前先介绍几个概念。

算法比较
v-bfs算法来和DP算法、SP算法比较,用以上3个指标来度量算法在权衡轨迹简洁度和精确度上的优劣性。
采用DP算法来作为比较对象,因为该离线算法是纯粹的基于位置信息来简化轨迹,同时也是非常著名的算法。采用ZP算法作为比较对象,因为该离线算法同样是纯粹地基于方向信息来简化轨迹。算法的时间复杂度和空间复杂度比较如表1。

对每一个速度阈值,用算法v-bfs:得到简化轨迹Tsim,根据公式求出简化轨迹Tsim与原始轨迹T的角度偏差,作为SP算法的输入值。用相同的简化轨迹Tsim求出每个轨迹段的轨迹点到轨迹两端点的最大垂线距离,所有轨迹段垂线距离的最大值即为DA算法的输入值。在图3中,v-bfs算法和DP算法的L(H)值随着
的增大而逐渐变小,当
等于6.0m/S时,L(H)近似相等,然而SP算法L(H)值先变小然后保持不变;表明v-bfs算法在
较小时能保证简化轨迹与原始估计的方向偏差;然而
大于0.5m/s时,简化轨迹与原始估计的方向偏差非常大。图3表明v-bfs算法的简洁性均没有DP算法和SP算法好。
在图4中,三种算法的(L(D/H)的值均随着的增大先增大后保持不变,且(L(D/H)在保持不变前,v-bfs:算法的轨迹一直处于另外两条轨迹的下方,说明v-bfs算法比DP算法和SP算法保留了更多原始轨迹的信息。表明经过v-bfs:算法简化后的轨迹比SP算法和DP算法的精确度更高。
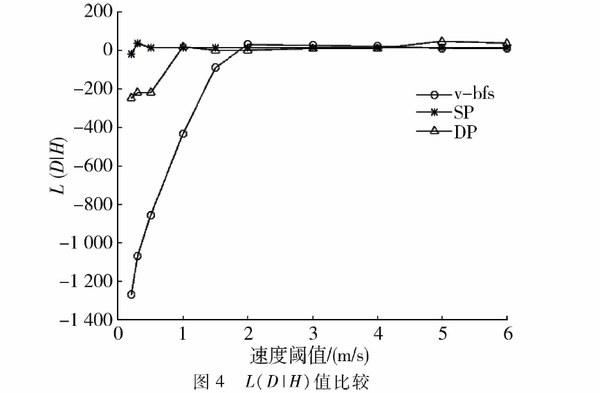
在图5中,当速度阈值小于1.5m/s时,v-bfs算法在权衡简洁度和精确度上都要比DP算法和SP算法好;速度阈值
大于1.5m/S时,经过三种算法后的简化轨迹与原始轨迹的总偏差大体上相差不大,并且随着
的逐渐增大,这三种算法效果一样。
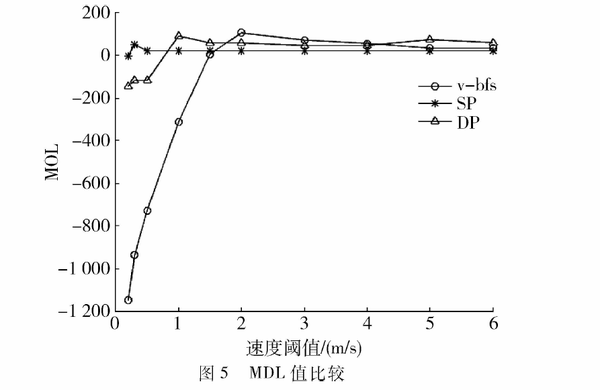
总的来说,v-bfs算法在简洁度上比SP算法和DP算法差,在精确度上比SP算法和DP算法要好,在权衡简洁性和精确性上比SP算法和DP算法也要好。
空间划分
根据定理1,要验证MI=是否成立,需要逐步验证MI=
i一
是否成立。[[
]]作为模型的一个划分,其定义的形式将直接影响空间划分的验证效率。
定理2设是模型M中的一个变量,{
0,
1…
n是
的取值范围,其中。是初始值:
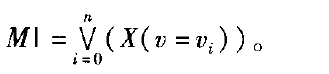
证明从初始状态So出发,若So共有n+1个可能的后继状态,其中变量的取值分别为0,
1,
2,⋯,
n,则模型的所有路径可以划分为n+1个子集,分别为,M0,M1,⋯,Mn,对于i∈{0,1,⋯,n}中的任意取值,都有:
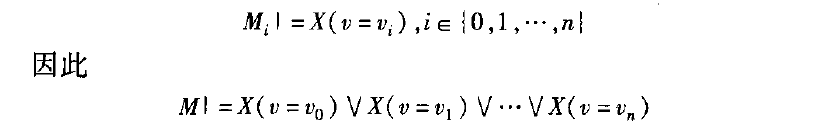
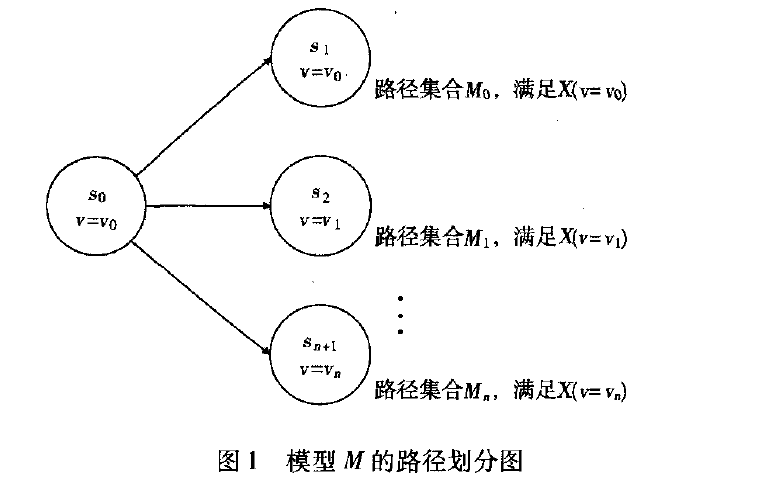
由图1可以得出,路径集合M1,M2,⋯,Mn满足式(1),所以这些路径集合上的状态在验证过程中无须遍历,只要对路径集合进行验证。同理当i=1时,只要对路径集合M1进行验证,即可达到搜索空间划分的目的。
实例
以可信系统中的隐通道(covert channe1)分析为例。因为隐通道利用了系统原本不是用于数据传送的资源来传送数据,所以这种通信方式一般不能被系统的固有安全机制所检测和控制。[3]其工作方式可以简单地概括为:一个高安全级主体使用某种操作更改了共享客体的某一属性在先,而另一个具有较低安全级或不可比安全级的主体借助某种操作观察到这种属性的变化在后。在状态机模型的约束下可以将隐通道的特征描述为:不同安全级主体依据其合法权限并按照某种规则交替访问同一共享客体的系统模型中的一组状态迁移序列。因此隐通道是最常见的隐蔽信息流。[4]
以一个包含m个主体和N个共享客体的一般访问模型作为分析对象,采用模型检测的方法进行隐通道分析。[5]需要指出的是,这是一个具有一般性的例子,在任意的代码片断中,当m个主体共享n个客体时,以下分析结果均成立。通过NuSMV的验证,上述公式在模型中满足约束条件,因此具有访问互斥性。
首先取共享客体数n=1,主体数m分别取2、5、10、15和20,原始模型的可达状态数和状态迁移数的变化情况如表1所示。抽象后的模型可达状态数和状态迁移数,如表2所示:
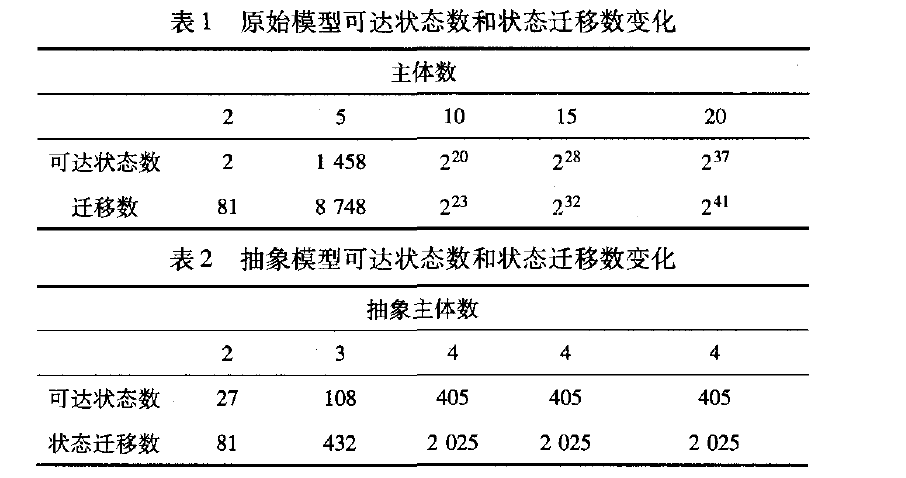
由于主体的密级集合SC:{TS,S,C,UC}只包含四个元素,且每一个主体的类别集合相等,所以抽象主体不超过4个。抽象后进行路径划分,系统情况如表3所示。下面取主体数m=10,共享客体数n分别取1、2、3、4和5。抽象后主体数为3。原始模型的可达状态数和状态迁移数的变化如表4所示。抽象模型情况如表5所示。
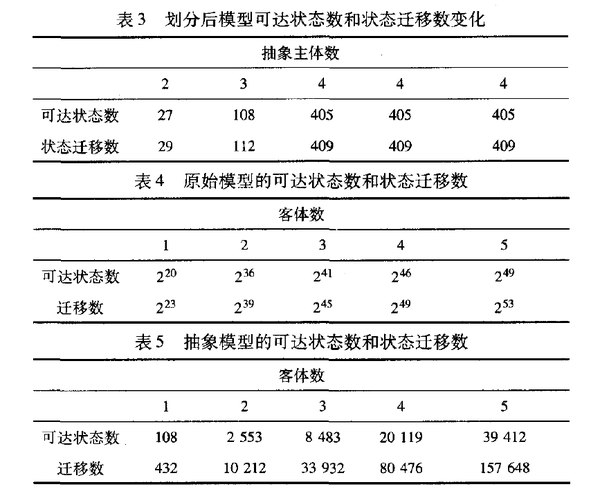
由于该模型中含有多个共享客体,首先划分客体,使每个子空间中只含有一个共享客体,因为本例中主体数已经确定。划分客体后,每个只含有一个共享客体的子空间规模是一致的,因此可以选取含有三个共享客体的例子作为分析对象,其可达状态数和状态迁移数的变化情况如表6所示。从中可以看出,经过抽象和客体划分操作后,原始模型的可达状态数分别约减了99.9%和98.7%;经过抽象和两次划分后,原始模型的状态迁移数分别约减了99.9%、98.7%和74.1%。

需要说明的是,表6中划分路径后,模型的可达状态数并没有发生变化,同为108,是因为划分路径后模型的主客体数并没有变化,只是在模型的众多路径中选取相应路径作为验证子空间,因此可达状态数没有变化,而状态迁移数发生了变化。
的抽象方法为一种一般性方法,抽象模型与原始模型的属性保持难以确定,且抽象只在一个维度上进行,因此本文的抽象方法更为精确有效。下面选取10个主体,1个共享客体的例子,分别用抽象方法与本文抽象方法进行隐通道搜索,对比情况如表7所示。[6]

抽象模型1表示使用抽象方法,抽象模型表示使用本文方法。从表7中可以看出,使用本文的抽象方法后可达状态数和状态迁移数更少。
从上面的实例可以看出,针对具体的隐通道问题进行抽象和搜索空间划分后,得到的待验证模型中包含的可达状态数和状态迁移数得到了有效约减,从而缓解了状态空间爆炸的问题。