网络爬虫的基本原理是什么?
11 个回答

关于网络爬虫原理,题主已经解释的很清楚了,我这里在补充下面两点
网络爬虫的更新策略
互联网是实时变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见包括:
1.历史参考策略
顾名思义,根据页面以往的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,爬虫系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
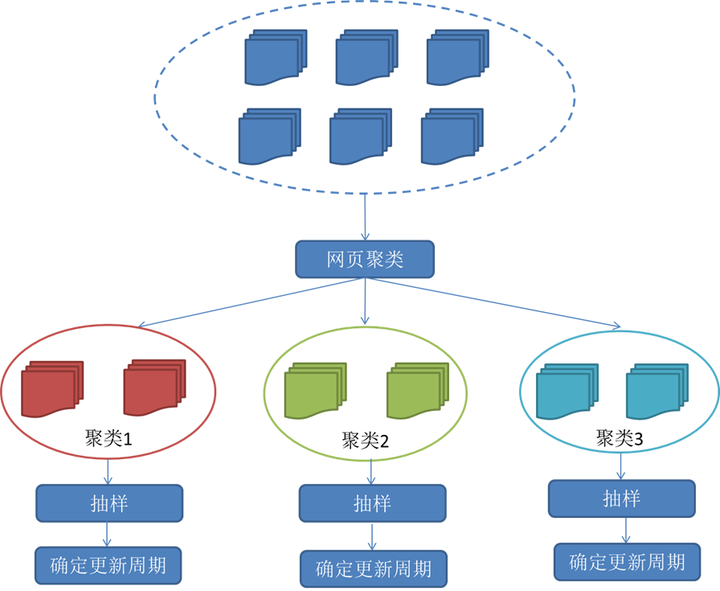
3.聚类抽样策略
前面提到的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一,系统要是为每个系统保存多个版本的历史信息,无疑增加了很多的系统负担;第二,要是新的网页完全没有历史信息,就无法确定更新策略。
这种策略认为,网页具有很多属性,类似属性的网页,可以认为其更新频率也是类似的。要计算某一个类别网页的更新频率,只需要对这一类网页抽样,以他们的更新周期作为整个类别的更新周期。基本思路如图:

网络爬虫的详细结构
一般来说,网络爬虫系统需要面对的是整个互联网上数以亿计的网页。单个爬虫程序不可能完成这样的任务。往往需要多个爬虫程序一起来处理。一般来说爬虫系统往往是一个分布式的三层结构。如图所示:
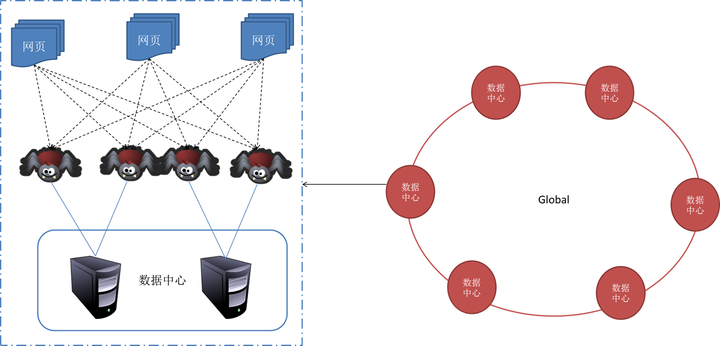

最下一层是分布在不同地理位置的数据中心,在每个数据中心里有若干台抓取服务器,而每台抓取服务器上可能部署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方式有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
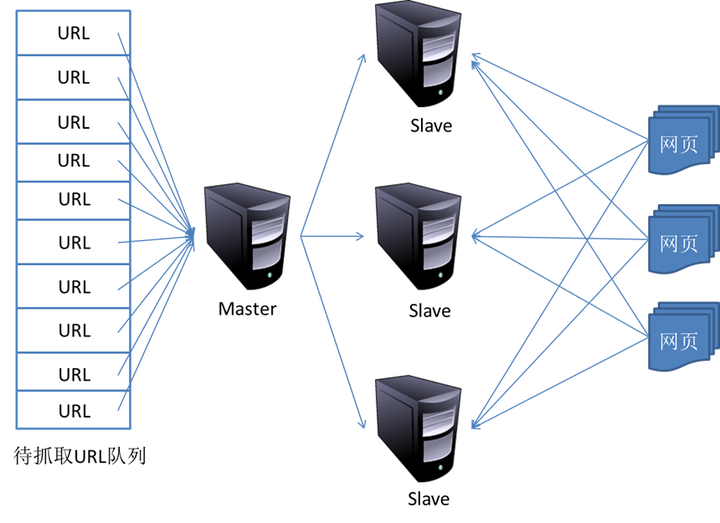

对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器除了维护待抓取URL队列以及分发URL之外,还要负责调解各个Slave服务器的负载情况。以免某些Slave服务器过于清闲或者劳累。
2.对等式(Peer to Peer)
对等式的基本结构如图所示:
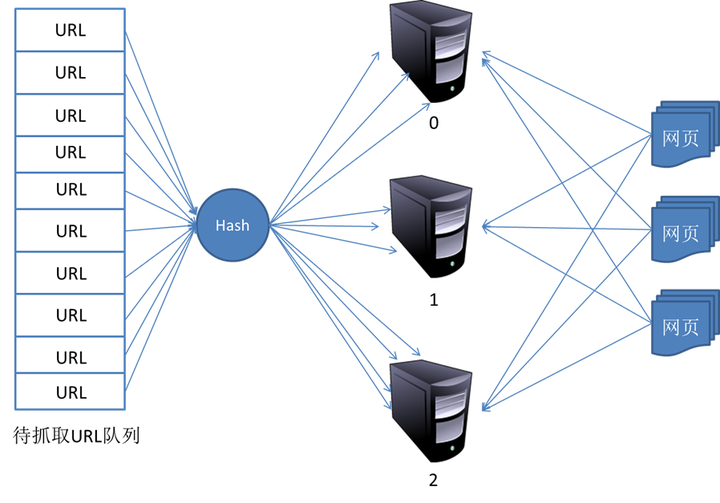

在这种模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后计算H mod m(其中m是服务器的数量,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
文章参考资料: https://blog.csdn.net/summerxiachen/article/details/51422246

初级爬虫工程师:


1.Web前端的知识:HTML, CSS, JavaScript, DOM, DHTML, Ajax, jQuery,json等;
2.正则表达式,能提取正常一般网页中想要的信息,比如某些特殊的文字,链接信息,知道什么是懒惰,什么是贪婪型的正则;
3.会使用re, BeautifulSoup,XPath等获取一些DOM结构中的节点信息;
4.知道什么是深度优先,广度优先的抓取算法,及实践中的使用规则;
5.能分析简单网站的结构,会使用urllib,urllib2或requests库进行简单的数据抓取;
中级爬虫工程师:
1.了解什么是Hash,会使用简单的MD5,SHA1等算法对数据进行Hash以便存储;
2.熟悉HTTP,HTTPS协议的基础知识,了解GET,POST方法,了解HTTP头中的信息,包括返回状态码,编码,user-agent,cookie,session等;
3.能设置User-Agent进行数据爬取,设置代理等;
4.知道什么是Request,什么是Response,会使用Fiddle, Wireshark等工具抓取及分析简单的网络数据包;对于动态爬虫,要学会分析Ajax请求,模拟制造Post数据包请求,抓取客户端session等信息,对于一些简单的网站,能够通过模拟数据包进行自动登录;
5.对于比较难搞定的网站,学会使用浏览器+selenium抓取一些动态网页信息;
6.并发下载,通过并行下载加速数据抓取;多线程的使用;
高级爬虫工程师:
1.能使用Tesseract,百度AI,HOG+SVM,CNN等库进行验证码识别;
2.能使用数据挖掘的技术,分类算法等避免死链等;
3.会使用常用的数据库进行数据存储,查询,如Mongodb,Redis(大数据量的缓存)等;下载缓存,学习如何通过缓存避免重复下载的问题;Bloom Filter的使用;
4.能使用机器学习的技术动态调整爬虫的爬取策略,从而避免被禁IP封号等;
5.能使用一些开源框架Scrapy,Celery等分布式爬虫,能部署掌控分布式爬虫进行大规模的数据抓取;



今天我将用我所了解的爬虫知识编写一段爬虫程序,简单的来说爬虫并没有那么复杂,大多数人都是因为无知而感到恐惧,下面我就不多说了,一起跟着我开启爬虫之旅吧。
爬虫是什么?
我们时常听说编程大牛嘴边一直念叨着“网络爬虫“,那网络爬虫究竟是何方神圣呢?
网络爬虫能够模仿用户浏览网页,并将所想要的页面中的信息保存下来。有些同学不禁要问:“我自己浏览网页,可以手动将数据保存下来啊,为何要写个程序去爬取数据呢?“道理其实很简单,程序能够在短时间内访问成千上万的页面,并且在短时间内将海量数据保存下来,这速度可远远超越了人工手动浏览网页的速度。
爬虫的原理
爬取网页的过程大致分成两个步骤:
爬取网页html文件
爬虫的第一步就是要模拟用户浏览网页,获取需要访问的页面。
模拟用户浏览网页的方法很简单,使用Java类库中的URLConnection类即可,这个类可以发送HTTP请求,并返回请求页的二进制数据,我们只需将返回的二进制数据转换成String类型,这些数据就是请求页的HTML文本!
//设置需要爬取页面的URL
URL url = new URL("http://www.baidu.com");
//建立连接,获取URLConnection对象
URLConnection connection = url.openConnection();
//将URLConnection对象转换成HttpURLConnection对象
HttpURLConnection httpConnection = (HttpURLConnection) connection;
httpConnection.setDoOutput(true);
//获取输出流
OutputStreamWriter out = new OutputStreamWriter(httpConnection.getOutputStream(), "8859_1");
//刷新输出流,然后关闭流
out.flush();
out.close();
//一旦发送成功,用以下方法就可以得到服务器的回应:
String sCurrentLine = "";
String sTotalString = "";
//ResponseCode==200表示请求发送成功! if(httpConnection.getResponseCode()==200){
//获取服务器返回的输入流
InputStream l_urlStream = httpConnection.getInputStream();
BufferedReader l_reader = new BufferedReader(new InputStreamReader(l_urlStream));
while ((sCurrentLine = l_reader.readLine()) != null) {
sTotalString += sCurrentLine + "\r\n";
}
System.out.println(sTotalString);
return true;
}分析html文件,抽取其中需要的数据
当我们获取到请求页的HTML文本之后就需要在一堆HTML标签中将我们所需要的数据抽取出来。这里给大家提供一个很好用的抽取HTML数据的第三方Jar包:Jsoup!
Jsoup提供了getElementById()、getElementById()等方法,我们能够很方便地将指定标签中的数据抽取出来。除此之外,为了方便实现网络爬虫,Jsoup中已经集成了发送HTTP请求的函数,而且将整个发送请求的过程极度地简化,只需两步就能完成,无需再使用HttpConnection类库在发送HTTP请求前进行一系列复杂的设置,并且Jsoup中返回的就是HTML文本,无需再进行二进制转换成HTML文本的操作。代码如下:
//通过Jsoup获取HTML文本
Document doc = Jsoup.connect("http://10.20.100.5:8080/").get();
//获取HTML中所有的tbody标签
Elements tbodys = doc.getElementsByTag("tbody");
//获取tbody标签中所有的td标签
Elements tds = tbodys.get(1).getElementsByTag("td");
//获取td中的文本
tds.get(0).html();看完这些相信大家对于网络爬虫已经入门了,能够实现一个最简单的爬虫程序,接下来我会带领大家一步步深入,实现一个更加智能、功能更加强大的爬虫!

爬虫入门,爬虫原理,爬虫基础理论知识

【高品质爬虫代理ip免费试用】
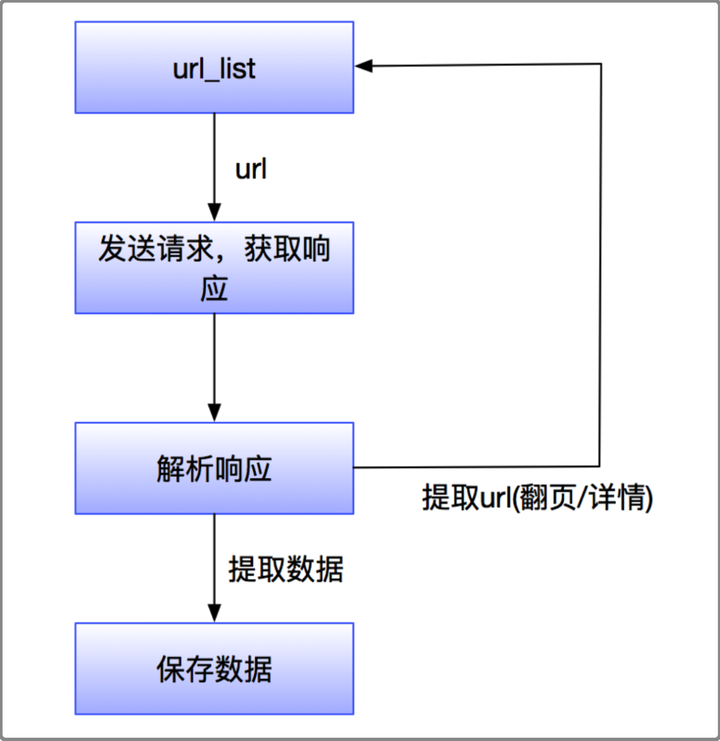
爬虫在浏览器工作原理中,所做的事情,就是替代"人"和"浏览器"这个环节,模拟他们的操作对服务器进行请求。
基本工作流程:
发起请求 -> 获取返回内容 -> 解析返回的内容 -> 存储数据
爬虫分类
通⽤⽹络爬⾍
例如 baidu google yahu
聚焦⽹络爬⾍
根据既定的⽬标有选择的抓取某⼀特定主题内容
增量式⽹络爬⾍
指对下载⽹⻚采取增量式的更新和只爬⾏新产⽣的或者已经 发⽣变化的⽹⻚爬⾍
深层⽹络爬⾍
指那些⼤部分内容不能通过静态链接获取的、隐藏在搜索表单 后的,只有⽤户提交⼀些关键词才能获得的web⻚⾯ 例如 ⽤户登录注册才能 访问的⻚⾯
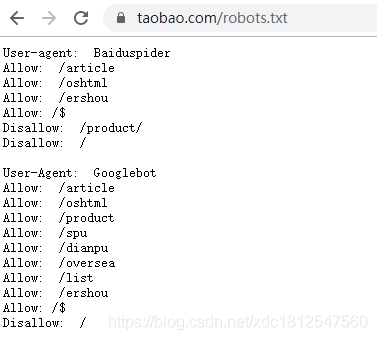
robots协议
「爬虫」在某种情况下会给目标服务器造成很大的压力,甚至导致服务器崩溃。
因此部分服务器运行商,会想方设法防止「爬虫」访问自己的服务器。
这里就需要谈到【robots】协议!
【robots】协议是国际互联网界通行的道德规范,基于以下原则建立:
1、搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
简单来说,它告诉网络搜索引擎的漫游器(也就是我们的「爬虫」),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
查看一个网站的【robots】协议只需要在该网站首页后添加【/robots.txt】就可以了。


我们下下面呢看一下抓取归因啊,影响网页抓取的因素汇总。搜罗爬虫抓取因素汇总全部节点啊,这是一堂抓取总结课系统全面的整理了影响专区的各维度的因素。那在抓取归因上呢,我给它分成了两个大类。第一大类呢是抓取效率啊,就是抓的这个速度上啊效率上啊。第二个呢是抓取的可识别性啊,就是我装完之后,我知不知道这个东西是什么啊?来看。抓取效率。第一个DNS解析啊,选择一个靠谱的DS商。啊,比如说美国的DNS商啊,我中国的DNS商,那我肯定选择中国的嘛,是不是?毕竟因这个我国制度影响嘛,会有一些个呃网站嗯不能访问嘛,是不是啊?所以说在一定情况下呢,我们选择国内的较为强大的域名服务商。一般这种哈比如说像阿里云的DNS解析,华夏名网易名中国等等啊,你我们都可以去尝试。那你想那这些哪个最好呢?嗯,哪个最好呢?我们可以通过什么?通过浏览器,我们之前演示过啊浏览器审查元素,对不对?F12键审查元素。审查元素,火狐浏览器啊有一个网络啊,火狐浏览器。有一个网络,网络里面,我们点开有个耗时。耗时里面,你第一次访问这个域名的时候,它就会出现。就是比如说DNS啊多长时间,然后其他多长时间多长时间,然后去看这个DS的时间。然后呢再看一下别的呃网站嗯的他们的DS时间啊,然后呢去对比。啊。然后呢在CDN加速这里呢。第一个是CDN节点的稳定性,节点的稳定性。我们之前也讲到过IP啊,IP地址,就是你CBN节点节点就是不同的地方嘛。就是比如说呃我这个网站呃,用了阿里云的CDN,阿里云在青岛,在上海,在河南,在等等各个地方都有节点。那当上海的用户访问我的网站的时候呢,阿里云直接让他们去访问了上海的那个CDN节点里面的缓存数据。然后呢,访问就是其他城市的访问加上就是他会呃阿里云的这个CDN会同步到最近的那一个。但这个中间的两个问题,你会不会今天让这个用户访问上海本市的,明天就会让他访问杭州的了。这个IPU就会变,而且今天也不稳定。第二种情况同样都是访问上海本市的。那今天访问明天访问或者上午访问,下午访问的IP会不会发生变化?针对于搜索引擎而言,我们应该做什么?回原处理啊回原处理啊。第2个C点支持的网络,网络是什么?比如说什么电信的、联通的呃,什么移动的等等啊,那这些你比如说。你你CDN是电信的网,用户里也是电信的网。那电信访问电信是不是更快?是的啊,这个这个是常识啊,我觉得嗯那呃如果说爬虫是电信,你的是。不支持的就是比如说你的那个指示不是多线呢,不是多线的这种啊,多线就是各种都有。你的是呃移动的啊,它电信访问移动是不是有朋友们?所以说一般不选CDFR,你是多线的,多线就是多种运营商的线路的啊。选择服务器一样啊,服务器的时候也是要这样的啊,一定是多线的啊。那在web在服务器里面,第一有web服务器,web服务器里面我们讲到了什么?最重要的http的报文,对不对?报文有那么多,大家一定要记住啊,做到你可以不会被记不住哪一个点。但是你要知道那些豹纹的具体的功能在你真正去优化网站去做这些基础优化的时候,这些点你要知道有这么一个东西是能够干这件事情。一定要知道。在AAPP服务器,APP服务器就是我们PRP嘛PRP或者是各种程序员数据库买circle。这两块啊它影响的是什么?是在这个专区耗时里面啊,还是这里面啊有一个等待啊有一个等待。这个等待。我重新写一下啊。这个等待,那就是想是他们俩综合的一个处理时间,就是我给你,我告诉你我想要什么了,然后他就等着等着结果返回。那这个等待的时间是多长?啊,他等待的时间是多长,就取决于你的数据库的这个优化之后的性能。你的程序优化之后的性能,你的整个web服务就是你整个服务器整体的一个性能的输出。如果你的这个等待整体时间过长。怎么办?赶紧找他们去解决啊,去问啊,去琢磨,去解决这些问题。然后机房位置啊,网络性能对,那机房位置就是。你如果没有用cdn的话啊,你你买的是美国的服务器和我是用的呃,北京阿里云的服务器。那同样爬虫去访问的时候,一定是我的速度要比你快位置。网络更同样的刚才提到了嘛嗯这个嗯。然后性能。性能就是服务器本身的一个配置。CPU是多少啊,带宽是多少啊,然后内存是多少啊,啊当这个数据库就是这个服务器压力大的时候,这个服务器本身它还能不能处理过来。就像比如说我们的电脑一样,你打开的东西多了,你的内存就满了。如果你装了360安全卫士,右边有个小球,对不对?小球告诉你内存还剩多少啊,你打开东西越来越多的时候,那个小球就就爆了啊,90%了。那个时候你的电脑就会很卡,夫妻一样的,他也是一台电脑,他也在处理很多的程序啊呃带宽你一兆带宽,四兆带宽。那下载怎么样?你从他的网站上下载东西哈,你的网速多少是一个因素。他呢下次就是他给你传输的速度是多少,也是一个因素。也就是说你网速足够快。并不代表着。你下载任何东西也都足够快,就他的那台机子这个网速很慢啊,就是下行的呃,应该上行的,上行的速度很慢啊,然后你下行,然后就是他就是给你给你传输不动那么大的带宽。他可能一他最多一小时给你传输过来,可能一兆一分钟给你传输一兆。但是你实际上是你是千兆贷款,你一小时能你一秒钟能大概能接收100兆,但是它只能一秒钟给你一照,一秒钟给你一照,就这种啊,所以这也意味着什么?你们平时在网站下载东西的时候哈,在浏览器上打开去下载一些东西的时候,有的东西下载哈,就有的网站下载的时候就特别快。有的网站下载特别慢啊,一个图片网站或者一个网站一样。你打开这些图片的时候也很慢啊。对,就都是这种因素。所以说带宽也是一种影响因素啊,我在14年的时候,我有一个图片的网站,当时还没有还没有扔。我加了我从两兆带宽变成四兆带宽,然后我的流量大概增长了40%。啊,这是带宽上,因为我那都是图片站,就是速度要求很很很强啊。然后再有的话就是网网页相关的,网页相关的第一网页自身的大小。啊,那静态网页大小啊,什么是静态网页的,静静态什么是静态文件大小呢?你的GS文件CSS文件啊,然后PNG这种图片等等这种文件,它的大小,特别是PNG文件啊。因为PNG文件啊就是我们的图片啊,有的人就直接呃我们从就是弄一张图片,然后拿下来,然后就直接传上去了。但这个中间要注意啊,比如说我平时用的我自己电脑是迈克。我编辑好了我的一篇博客的文章之后,我这张图片哈,我比如说通过一些截图什么东西拿下来哈。这张图片最小大概是一兆多啊,可能图片的尺寸并没有,就我根本不需要那么大。我的网站上最大的尺寸,我我是600乘3 69啊,它可能是2000乘乘N乘乘乘1000几和乘乘多少。那在这种情况下怎么办?我给他缩小,然后我就又又用了PS把它缩小。缩小之后呢,我为了再减少它的大小哈,我PNG的格式的图片会比勾PG的要大。我还会再把它另存勾PG格式啊。QPG格式啊,然后再保证它的清晰度可变可见性哈都完全没有问题的情况下我会做这件事情。然后呢保证我这个图片的这些大小问题。然后第二点的话就是我网页自身的注释代码啊,就是很多他们前端人写东西的时候,就是你右键查看浏览,右右键查看源代码的时候有一堆是绿色的代码,其实都是没有用的啊,那是被注释掉的。就是它就是没有效果了,就再往下存着。这些代码完全没有意义了,你就删掉吧,别的也影响网页大小,对不对?啊,那可能他只占到了嗯。20个字节。那如果爬虫每天20万抓取量。加上爬虫,每天20万抓取量,然后你有10万个页面,你算一下这20个字节影响多少东西。啊,很可怕的也是啊。然后下面非合理的代码布局,就本就是这个代码布局就讲到我们的DVCSS那种布局格式嘛。本身你一个DIV里面嵌套一个A就能解决的事情。你非要DIV,然后ULLI,然后呃什么P然后再A你说你这些是不是都是多余。啊。所以我们呢也要学一些个这个前端的知识啊前端的知识,然后去淘宝上嗯五块钱就能买一套这种东西啊。对啊,嗯然后去达人了解一下啊,然后掌握这些东西,精进自己的这些个综合能力。然后还有就是加载文件的数量。之前我们有提到过你这一个一个网页本身哈,有十个js文件啊,十个js文件,十个css文件。那你想趴中在这装上去,你整个网页的时候,就是比如radar爬虫,特别是啊他要他什么,他去加载你10个GS文件,然后呢再去抓取你10个GS文件里面的内容。如果这10个GS文件我要能合并成一个呢它就是什么只加载一次,也只抓载,你也只那个抓取一次,对不对?那这样上来说是不是更优的?啊,所以说从加载文件的数量上,以及这个网页本身的注释代码非合理布局,我们都要去控制。包括在静态文件的这个它的这个大小上啊,GS文件啊,CS文件啊,我们尽可能的去缩短这个GS文件,或者说这个图,特别是图片的一个大小问题。然后呢也要去控制这个什么加载的文件的加载数量,然后注释代码等等这些问题。但这些这些并不是绝对的标准。记住啊这一点很重要,这些并不是绝对的标准。绝对的标准是什么呢?是你和你的前端人员,就是你和你这个协议这个网页的前端的人员沟通的时候,他认同了你,然后改正了,那是最好的结果。你不要上来就告诉他做SO就得这样做啊,然后就得经典量了才有一缕优化。那他就会说,那我这样的布局是没有问题的呀。然后GS文件我们分成了两个,一个require,然后一个然后一个轮播图的,你非要让我把轮播图放到这块的这个框架里面,不靠谱啊。你就撞墙了啊。啊,所以了解一些这些知识,了解一些这些知识。好,这是那个我们讲的抓取效率。再来看抓取可识别性。这个呢我相信大家啊都很明白。但是为了课程本体的全面性,我我还是过一下啊第一项。javascript也就是呃GS的简称啊,GS它简称GS,然后A勾A叉啊,阿贾克斯阿贾克斯是他下GS下面的一种技术啊一种技术。啊,一种技术。那既然是本身的东西,我们之前也有提到过,它是能够抓取的,对不对?它只要右键查看源代码能看到的网页,盘中就能抓取右键查看源代码看不到的。那么通过百度spider rider爬虫,然后阿亚克斯里面呢他也能够审查元素里面的东西,他也都能看到。那在这种情况下。我还是更希望就是让网页爬虫看到所有的内容。那这个时候那你就要少用什么阿贾克斯里面东西,让更多的那种什么在源代码里面出现啊。第二,音频视频。音频视频本身的话,我们也可以加一些属性啊,然后去标注我们的音频视频去做什么。我不知道现在ATM25呃用的什么标记啊,大家可以看一下,这个就是这个这个点就行。然后还有图片的out属性,out属性里面我们可以加关键词,也可以加这个你这篇文章的标主题,标题也可以加你这个图片上下文最关联的紧密的那个关键词也可以。最呃但是最好呢还是设置好这张图片本身的。如果它就是一个配图啊,你看我那个网站,就我的博客就会有很多配图。那我怎么去写呢?我就写。文章标题就是我先把这个文章的标题写到这个out属性里面,后面加四个字儿,配图,加俩字儿配图投图啊,就这样。我并没有作弊,这就是这篇文章的头图嘛,对不对?然后flash动画文件啊,我觉得这个基本上没有没有用的了啊。对,但是你要提一下呃,万一可能你你入行不久,呃,比如说一年两年,你你没有不知道这个flash动画文件。然后大家还是要清楚一下啊,甚至有些有的网站的一些轮播图啊,图片还是在用这种东西啊。对,所以不建议这些东西。然后还有就是。嗯。关于图片的导航。啊,关于图片的导航。对,就是呃我我实际上最近又我不知道是强还是什么情况啊,就是短期内发现了两个网站啊,都是在用这个图片这个形式去做导航呢。实际上这种形式不可取啊,我们还是这里面要取文字啊,我觉得这个应该。呃,很呃这这是常识啊,我觉得。对,门子里面,然后有可能的话包含关键词。嗯,嗯没可能的话就正常写什么就是什么就可以了。对。ok那这个呢就是我们整体上抓取归因上所讲到的这些点。这里啊重点上来说。还是我们在这个抓取效率上的这个提升上。然后这些点啊下面呢我们的归因的点哈还会有输入的归因,排名的归因。然后从抓取收入排名都总结出这样的一个归因。然后呢,你们你们在每一个这个归因的后面哈,我这个数的后面哈再罗列出那些细的更细的点,总结出一个大的思维导图,你们自己去整理,去总结啊,自己去整理总结。这样呢你就会有一个很系统的一个大的GSSU的基础优化的大表。未来做任何网站的时候,所有的这一套东西做顺了做通了,ok啊,成功了80%,成功了80%。好,那下面呢我们看一下哈有什么问题大家啊然后我们来一起讨论一下。然后轻易的问题一。啊,有问题大家发给珍惜老师啊,发给珍惜老师啊,然后轻易的问题一,未收录页面标题青毛。燕窝图片UL是这个在收录区域的某文本文字写上。燕窝图片。可以吗?还是要把未输入页面的标题写全?可以的啊,但我建议你的这个毛文本啊写的还是呃一个长尾词落地到对标的长尾词,这样会更好一些。因为燕窝图片本身这个词你给到这样的一个文章页是没效的啊。就是他不可能获得这个这个排名的一篇文章,对不对?除非你以后所有的燕窝图片都连接到这一篇文章上,不可能吧。就是你燕窝图片对应的应该是你那个图片的那个频道页,他做的是燕窝图片这个词。而这篇文章讲的是青毛燕窝图片,那应该链接的是青毛燕窝图片。啊,这个要要清楚。第二个问题。herself title嗯轻毛燕窝图片轻毛燕窝图片。然后第二种。抬头然后。这两种写法对轻薄烟雾图片的排名有无影响?我看哪里变了啊?你的title。嗯,也可以这样写可以这样写。我觉得还是第一种好啊,这种好啊,就是直观一些。如果说你的那个呃网页上就写着这么多字啊,就写不开了。那你可以这样缩写啊,但如果写得开的话,还是这样写啊。对,但我觉得六个字儿不可能写不开啊。啊。好啊,我们再来看下面的问题。有种自恋叫小小鱼儿啊。网站被采集,但是每个ip都是不同的一个ip只访问桩取2到3个页面,然后又换了IP这种情况怎么防止采集?嗯,IP不同UA相同吗?我们可以通过啊几个几个维度。UA啊。然后IP。然后。然后去记录什么去最好还能就是你如果真的想解决采集问题啊,就是因为我在这里做这件事情,嗯,还要做一下这个嗯嗯。访问时长嗯,然后。咱跳出来就其实防守比如说。小鱼。小一秒。然后就这种。对,然后去做这件事情,然后去屏蔽,然后通过UA和IP。但如果你说哈它的一个IP对应一个UA,然后。只访问两三个页面就就撤了。那这种情况下啊,你没有办法解决啊,你没有办法解决,为什么没有办法解决呢?他怎么换呢?是不是你这个IP那个又来了啊?他就装三个页面啊。但你也太奇葩了啊,这种情况太少了,少的可怜啊,他一个IP的成本就就不什么,然后他才赚你两三个页面。我觉得这种概率可能你你再好好分析一下你的网站这种情况很少存在啊。有嗯还是阿贾克斯抓取的数据,是否可以全部屏蔽掉,有用的就不要屏蔽,没用的就可以屏蔽。再来看啊。智者横尽。安装完直接就可以编译python了吗?还需要配配置吗?需要的啊呃我们呃就大家可以网上搜一下啊,实际上的话我们呃下载完那个sublime之后,下载完python之后哈,还需要在这个比如说我电脑啊属性点开属性之后,高级系统设置里面。高清上面有一个什么环境变量,打开环境变量,在环境变量里面哈找到什么?找到路径啊,找到这个PATH啊,然后点击编辑。把你的那个路径添进来,你看我这里啊,我我把拍子装到C盘一下,建议大家也装到C盘一下。因为这个东西嗯我习惯性的装到C盘下,它默认也是C盘下。最后加上银行这个注意啊,每一个这个环境变量中间这个分号分隔的,然后后面加上就可以了。啊,后面加上就可以了。啊,注意注意这一点啊,大家。也把那个环境变量设置完成之后的话,你打开那个这个工具,按control b就可以了。如果说你用的是非windows系统,或者说中间存在问题啊,去百度上搜索一下sublime,然后配置python环境或者说。windows系统或者max系统设置环境变量啊,这个都很简单啊,往上一搜就是图文的教程就全出来了。嗯。那我们再来看下一个问题。一个页面从200到400,然后再到200,这个对收入会有影响吗?一个页面从200到400,然后再到200是什么,到400到200。最好具体一点啊。对这个问题。呃,状态码404是吧,404。嗯,404ok。一个页面一个页面从2002200到40,然后再到200,这个对收入会不会有影响啊,不会有影响。呃,你的做法应该是这样的就是。不是从200到4不行不行啊,一个页。如果你这个页面是错误,页面就必须直接是404。必须直接是404返回状态码。不能中间还还还还有几层啊,不能的啊。如果你当前页面就是错误页面它返回的状态码必须直接是404,不能是301,不能是302,也不能是其他。好吧,这个点一定要记住啊。当然嗯你也可以做一次301,你也可以做一次301。因为爬虫抓取两层301就是它301之后呢会再录入到这个页面。就是然后如果再录,到时候再是30,他就不抓取了。那这个但是呢如果你上一个页面是错误页面,你申请到了另外一个页面,然后呢,是404也行啊。然后他追加的这个这个情况是这。就是有一个页面上线了,但是由于内容问题被下架了,然后重新上架的UL链接是不变的,这种也有关系吗?没有,就是如果说你只是短期的这个一个呃,就是因为你的这个情况问题导致一些问题哈呃是没有影响的。就是什么,你比如说你一直以来都是从260到4046到200,这样就不靠谱啊。但是你要是说你只是某一个时间点,它先是200,然后下线了变成404了,然后你又上线了,他又回来了,这个是没有影响的。你的设置本身是对的啊。对,这个理解可能有点偏差啊,我觉得对,就是第一次访问是什么页面?对了,就是200页面错了,就是404就可以。你上了下什么呢?这个这个无所谓,影响。啊。然后来看一下。那个文熙的问题啊,关于导航的疑问,网站分类越来越多。可不可以在设置导航的时候,将同一大类按照细分小类划分导航栏。网站分类越来越多啊,就是网站的类别越来越丰富了。可不可以在设置导航的时候,将同一大类的按照细分小类划分导航栏。按照同一大类。将同一大类哦,我知道了啊,可以的啊,可以这样做的啊。呃,如果你要这样做的话呃。其实就是常规的去做啊,我的理解实际上你可能你可能啊你看我描述对不对啊,你在讨论区然后给我回复啊。我的理解呢是什么呢?就是呃你的整体的这个状况,就是你的网站的类目更多了,分出来了大类跟小类每一个大类下呢想包含N个小类。就比如说类似于京东那种网站啊,那这个先看到的是几个大类,鼠标放上去呢又划出来一堆小类。然后呢这样的一个操作呃,对不对?不是啊,嗯那我可能还没有完全明白你的问题。呃,我你可以再描述一下你你再追加一下这个问题吧。然后我我可能没有太理解。主导航栏,这里按照大类划分成小的,但不会在主导航栏里面显示其他的。可以可以,没问题的没问题的。但是你的展现层级上,你要注意一个点什么。就是呃无论大类小类,一定是本着那个搜索需求更高的,然后呢去做排列你展示的这个更多的就是你展示出来的靠前或者靠后的,一定是没有展示那些啊低于这些的搜索量,低于这些用户需求或者这些的。就是比如说内容的丰富度比之前更高啊,然后基于这三个点。然后去做这件事情啊,整体上来说这样做本身是没有问题的。需要注意的话就是三个点啊再重复一下。第一。就是。展示出来的搜索量一定是最高的啊,就是比那些没有展示最高的。然后第二展示出来的点击进去的内容的丰富度一定是呃也是高于其就是那个没有展示出来的。对,然后对,就这两个点2个点2个点。嗯。对对对,内容重复度高。然后我看到了智者恒定,说有没有效果好的制作师推荐我们学院内部用啊。呃确实我我一直以来哈没有没有在没有用过蜘蛛吃这个东西,对我根本不需要用这个东西。所以说呢身边呢也没有说这个。我可以帮你们帮大家问一下啊,问一下,然后看看呃给推荐推荐给大家。到比如说什么内部用的,因为只有这个东西哈,就是我觉得如果你的爬虫啊,就是你要先看什么,看你整体的这个抓取是不是够够是是什么意思啊,不是说你抓取量小啊,就就不好。你每天就发一篇文章,网站总共就200个页面,然后你有20个,每天20个抓取你的抓你的整体页面量对比抓取数的话是10%啊,就不小了啊。所以你要去综合的去判断一下自己的这个。嗯,整体的这个抓取啊,就是你到底够不够,不是抓取少就是不好,是您网站现有的这个体量也就满足了这样的抓取,而抓取更的更多的量是就抓取更多会存在哪几个点呢?两个维度啊,第一最重要的维度就是你新内容产生的频率高。你每天产生500篇内容,500个页面和你每天只产生两个页面,你的抓取频率一定是不一样的。啊,如果说你网站一周才产生几两篇文章,三篇文章,那你现有每天比较平均的一个抓取哈。也就是一些针对于历史更新策略,用户体验更新错了,激励抽样策略的这样的一个抓取的一个分配的体量,而并非针对于你的新增内容啊,你就每天产生两个内容。那我干嘛还要派100个蜘蛛来抓取你的网页呢?苏州你应该会有自己的判断逻辑啊。对,千万不要总觉得抓取好就好,抓取多就好,不一定的啊,抓取多了有时候就是过剩,过剩就是浪费,还会影响服务器资源啊。嗯,大家还有问题吗?蜘蛛总来抓某一个页面是不是给屏蔽掉?嗯。我把这个问题也是复制出来啊,总忘了这件事情,蜘蛛总来抓取抓某一个。页面是不是是不是给屏蔽掉这里哈有几个条件啊,第一。这个页面有用吗?有搜索价值吗啊?考虑一下,然后判断一下。第二。能不能利用这个页面?提升。引导吧,引导抓取其他被抓取的页面。嗯。然后第三。屏蔽。之后的好处是什么?啊,然后考虑一下这三个点,然后呢,你再去考虑要不要屏蔽它。我觉得哈如果没有搜索价值,我也可以说利用这个页面呢去引导抓取其他的页面。然后没必要是直接就把资源给我不要了。对,就是我我今天给你十块钱,你收着了然后你够用了,明天我又给你十块,你说我不要了,我够了,我够了,不要不要了啊。这个呃两个逻辑啊,这是所以说一定要什么现有资源做到合理利用,哪怕就是在服务器稳定,服务器就是正常没有影响的情况下,我资源过剩也是可以的。因为你这是。自然性过剩,而不是像比如说我用了蜘蛛池什么的,叫嗯刻意性过剩。刻意性过剩的话,你就要考虑更多的这个在维度上的点啊,就比如说中间我我可能用支付宝要花钱,但花完钱之后带来什么效应呢?没有,那就不靠谱,对不对?啊,整体上要大家要考虑这些点。好啊,那课那行,那今天呢我们的课程呢就先到这里。嗯。抓取频次多少算合理,没有标准。对我再强调一下啊。就是SU里面没有没有任何一个点是有标准的,不要再去问标准,这样的事情没有标准,什么东西都没有标准。他都是就是因时因景因差而定的。比如说抓取频次多少算合理。我举个例子啊,抓取频次10万算合理。你的网站上只有200个页面,你能做到10万的抓取量吗?每天。那智联网站每智联招聘的网站每天有10每天能够新增16万到20万个页面。然后他要是有抓取频,抓取频次是200的话,那你觉得合理吗?你的网站对标你的页面量,对标你的新新增内容量。整体上它都是不均的啊,不等的情况不一的,没有具体的标准。你不能说你在这个网站是个企业站100个页面,你明天加入了一个中大型网站,它有5万个页面,10万个页面你用头像。哎呀,没事,我之前的网站也是每天20个,抓取速度都挺好。然后现在咱们虽然每天发300篇文章,放心吧,抓取20个没问题的。我之前经验告诉我的不靠谱啊,没有这样,没不要定标准定下限,那给你一个思路是什么?你去检测你的收入。如果你的页面都收录了,那你要抓取的目的是什么?想想。反应过来之后嘛,就是一定是更新。对不对?我我页面发生更新了,我需要更多的收入,我需要保证一个正常就是稳定性的一个在盘中更新策略上一个频次,对不对?他这个频次哈是没有定没有定向关联的,没有定量的也是啊,还是根据网站的体量。整体上来说,如果是必须要做一个定量标准的话,其实真的特别不好做啊特别不好做。因为什么?那你这连31个页面20万抓取量,那我能定20万除以3亿吗?这样这样的比例到你的网站上可能200个页面。那你你那个比例特别大了啊。对,所以这个千万不要考虑什么合理性或者说标准啊这些东西啊不建议去这样去做这些事情啊。一个企业网站四兆独立贷款速度算不算好?你带宽够了,别的呢啊一个企业网站四套贷款已经很厉害了啊。嗯,对,假如某一个页面总被抓取,我开出一块区域来放未抓取的链接,然后这些链接定期更换,这样可可以的啊可以的啊。你想一下你的网站的最新文章,热门文章啊,什么编辑推荐或者说相关文章啊等等这些,它都是不定期,可能每天都会。比如说最新文章,可能每天都会变,然后热门文章可能每周都会变。然后相关推荐可能每个月都会变,那都没有问题啊。对,变没有问题,没有说谁说没有谁说是就就就一成不变的,都可以变啊,都可以变啊

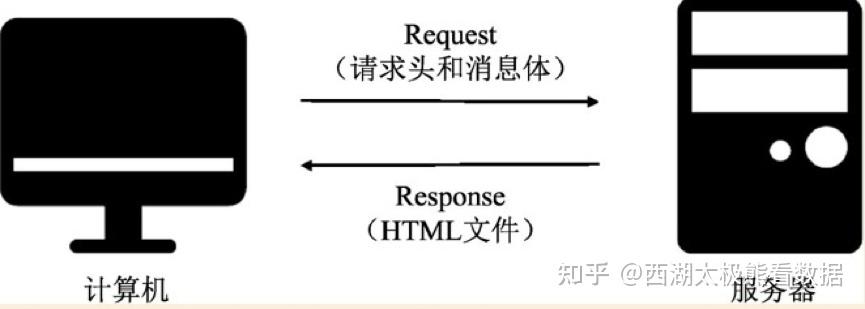

学习爬虫其实没有那么复杂,更多的是要了解网络连接的方式,以及我们每天和网络之间交互的方式。
- 网络连接就是计算机和服务器信息交流
- 爬虫就是伪装计算机和服务器交流获取情报
比如:网络连接就像我们平常搜索信息的时候,比如在百度搜索:数据分析,就相当于计算机给服务器发起了相应的搜索请求,然后服务器会返回相应的搜索网页结果信息。
如果要爬取搜索的结果信息,那就需要通过代码也就是爬虫,伪装模拟成我们平常上网的行为,向服务器发起请求来接收服务器端返回的内容,将其获取存储到本地,也就完成了爬虫的过程。


伴随着互联网的不断进步,人们获取数据的方式也在不断更新迭代,如今通过网络爬虫爬取网页进行数据采集已经成为了主流的数据获取方式,不过对于许多用户而言,爬虫程序经常使用却并不熟悉其工作原理,接下来就一起来了解一下:
构建数据提取脚本
一切都始于构建数据提取脚本。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的scraper bots。Python凭借其多样化的库,简单性和活跃的社区等等优势,成为编写Web抓取脚本的最受欢迎的编程语言。这些脚本可以实现完全自动化的数据提取。他们向服务器发送请求,访问选定的URL,遍历每个先前定义的页面、HTML标记和组件。然后就可以开始从这些地方提取数据。
开发各种数据爬取模式
用户可以对数据提取脚本进行个性化开发,可以实现仅从特定的HTML组件中提取数据。用户需要提取的数据取决于业务目标。当用户仅需要特定数据时,就不必提取所有内容。这也将减轻服务器的负担,减少存储空间要求,并使数据处理更加容易。
设置服务器环境
要持续运行网络抓取工具,一台服务器自然必不可少。因此用户需要投资服务器等基础设施,或从已建立的公司租用服务器。自有服务器可以允许用户每周7天,每天24小时不间断地运行数据提取脚本并简化数据记录和存储。
确保有足够的存储空间
数据提取脚本的交付内容是数据,而大规模数据就需要很大的存储容量。所以确保有足够的存储空间来维持抓取操作非常重要。
数据处理
采集的数据以原始形式出现,可能很难被人所理解。因此,解析和创建结构良好的结果是任何数据收集过程的重要组成部分。
IPIDEA已向众多互联网知名企业提供服务,对提高爬虫的抓取效率提供帮助,支持API批量使用,支持多线程高并发使用。

经过前面Python基础内容的学习,相信好多小伙伴都感觉一身本事,但是无用武之地吧,哈哈哈。。。
不要着急,如你们的愿,在爬虫阶段,我们就大胆的把基础部分的内容应用一下吧~~~
此时此刻,你准备好了吗?我们要开始爬虫的学习之路喽!

初识爬虫
一. 爬虫简介
模拟浏览器,发送请求,获取响应
网络爬虫,英文名为Spider,又称为网页蜘蛛,网络机器人,在数据分析应用中,更多的将爬虫称为数据采集程序,是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。
- 原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
- 爬虫也只能获取客户端(浏览器)所展示出来的数据
网络中的数据可以是由web服务器【Nginx/Apache】,数据库服务【MySQL/Redis/MongoDB】,索引库,大数据,视频/图片库,云存储【阿里云的OSS】等提供的,最主要的来源是Web服务器。
不过,大家一定要注意哦,可爬取的数据必须是公开的,非盈利的,如:如果侵入人家非公开的网络,人家会通过ip定位到你,属于违法行为的哦,再或者,一些理财的网站,如果爬取数据,肯定是不可以的,如果小伙伴们不听话,非要去爬取,那任何人都是保护不了你的哦,狗头保命~~~
有名的爬虫案件:简历大数据公司“巧达科技”被一锅端、“车来了”涉嫌偷数据被警方立案等


二. 爬虫分类
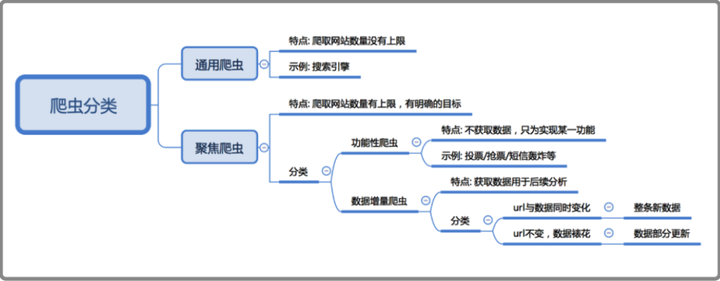

通用爬虫:
通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果
大家要注意哦,通用爬虫虽然简单,方便,但是缺点也是显而易见的,宋宋给大家列举了几点,大家可以了解一下:
a. 通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
b. 不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
c. 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
d. 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
聚焦爬虫:
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息,如12306抢票,或专门抓取某一个(某一类)网站数据。
1.根据是否以获取数据为目的,可以分为:
- 功能性爬虫,给你喜欢的明星投票、点赞
- 数据增量爬虫,比如招聘信息
2.根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
- 基于url地址变化、内容也随之变化的数据增量爬虫
- url地址不变、内容变化的数据增量爬虫
看到这里,大家是不是发现通用爬虫简单,但是不实用,聚焦爬虫应用比较广泛,而且实用,但是实现起来难度较大,不过没事的哈,有宋宋的帮助,我们都能学会的,奥利给!!!
三. 爬虫的作用
爬虫在互联网世界中有很多的作用,比如:
1. 数据采集,比如:
- 抓取微博评论(机器学习舆情监控)
- 抓取招聘网站的招聘信息(数据分析、挖掘)
- 新浪滚动新闻
- 百度新闻网站
2. 软件测试
爬虫之自动化测试
自动化测试所必需的selenium . selenium是一个用于Web应用程序测试的工具,selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE,chrome和Firefox等。其实就是借助于selenium做爬虫的事情。
3. 抢票和投票
- 12306抢票
- 投票网
4. 网络安全
- 短信轰炸
- web漏洞扫描
四. 技术步骤
第一步:爬取数据,实际上就是根据一个网址向服务器发起网络请求,获取到服务器返回的数据
第二步:解析数据,将服务器返回的数据转换为人容易理解的样式
第三步:筛选数据,从大量的数据中筛选出需要的数据
第四步:存储数据,将筛选出来的有用的数据存储起来,如:数据库,CSV文件,Excel文件,JSON文件等
只要小伙伴们按照这四个步骤操作,实现一个爬虫任务还是很简单的。

好了,我们本节课的内容就到此结束啦,通过本节课的学习,我们对爬虫有了大概的认识,并大概了解了爬虫相关的一些相关技术,有了这些概念的加持,对我们学习后面的内容会有很大的帮助。
如果你在学习过程中遇到任何问题,都可以联系我们加入免费体验课。
期待大家学习完爬虫的全部课程之后,能有一个不错的收获~~~,Good Luck!!!

Oxylabs为您列出了可以在不被列入黑名单的情况下,成功完成网络爬取的一些操作方法:
1、使用代理。代理和网络爬取(以及抓取)齐头并进。在您的设备和您正在抓取的网站之间使用中介可防止IP地址被封禁,同时为您提供匿名性并允许访问您所在地区可能无权访问的网站。
2、轮换IP地址。如果您从同一IP地址发送过多请求,网站可能会怀疑您是恶意行为者并阻止您的IP地址。同时,代理轮换使您看起来像许多不同的互联网用户,从而减少了被封禁的情况发生。
3、使用CAPTCHA(验证码)解决工具。要绕过CAPTCHA,请使用专用的CAPTCHA解决服务或现成的爬虫工具。例如, Oxylabs的数据抓取工具为您解决CAPTCHA并提供即用型结果。
4、使用真实用户代理。真实用户代理包含由自然访问者提交的流行HTTP请求配置。由于网站可以轻松检测到可疑的用户代理,为了避免被阻止,请确保自定义您的用户代理,使其看起来像一个自然访问者。
5、改变爬取模式。如果您的爬虫配置都是以相同的模式浏览网站,那么您将很快被封禁。您可以添加随机点击、滚动和鼠标移动,让您的爬取看起来较为不可预测;然而,这种行为不应该是完全随机的——最好参考一下普通用户是如何浏览网站的,然后将这些原理应用于工具本身。
除了上述列出的方法外,在Oxylabs的这篇文章( 如何在不被阻止的情况下抓取网站)中为您列出了更多详细内容,欢迎您继续阅读了解~如果有任何问题,您可以随时在线留言获取专业解答!