如何实现图的深度优先和广度优先搜索?
7 个回答

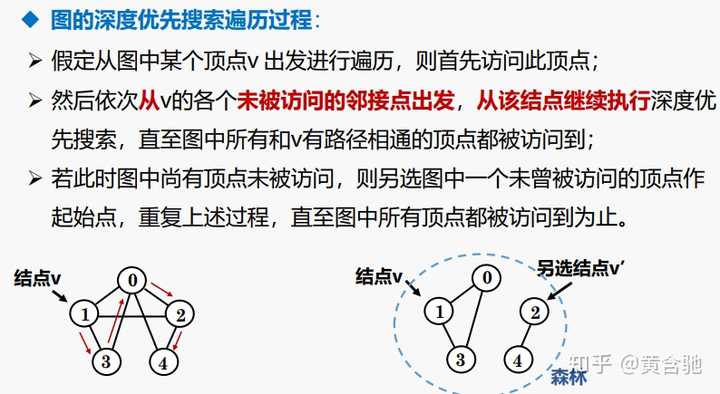
图的遍历
图的遍历是指从图的某个顶点出发访问图中所有顶点,并且使图中的每个顶点仅被访问一次的过程 图的遍历算法主要有深度优先搜索和广度优先搜索两种
深度优先搜索遍历

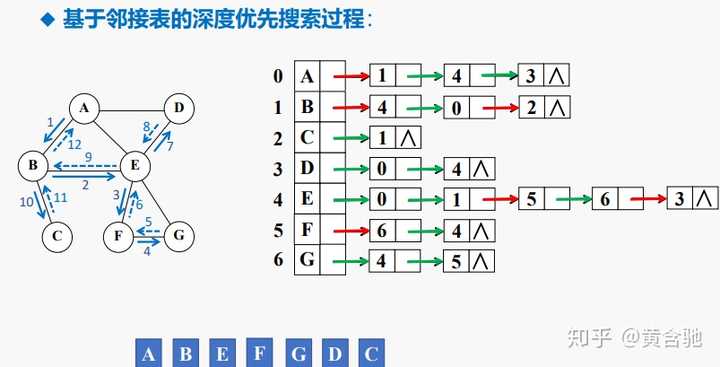

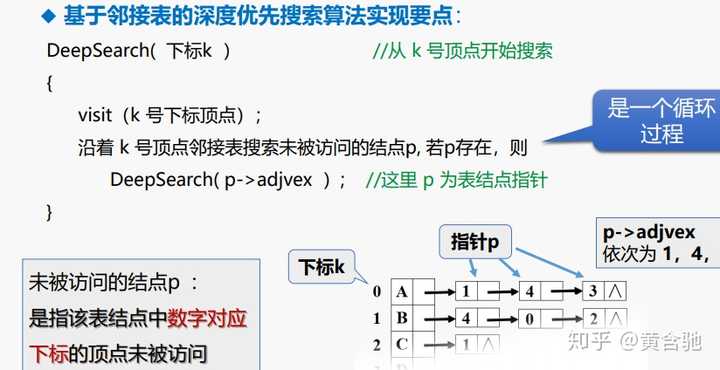

基于邻接表的深度优先搜索算法实现


广度优先搜索遍历
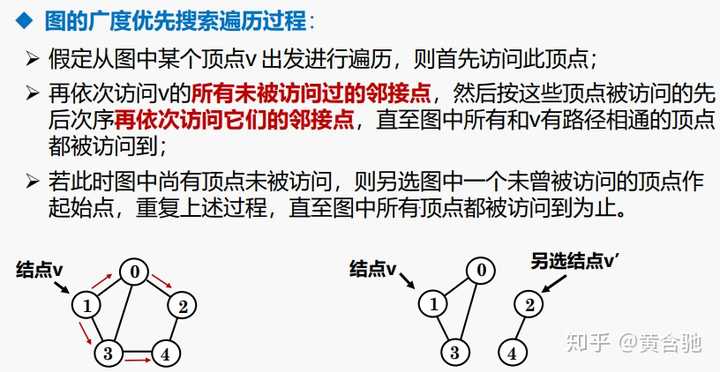

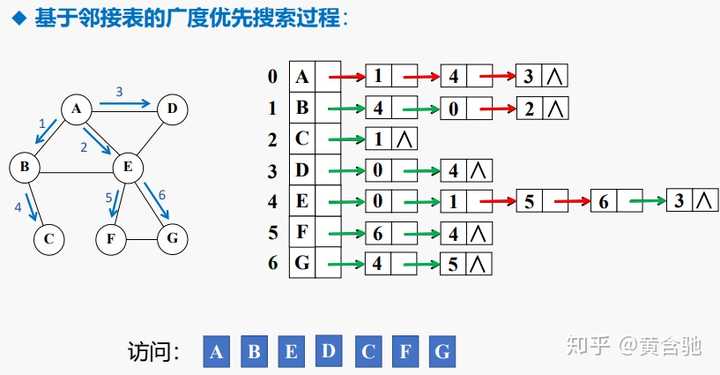

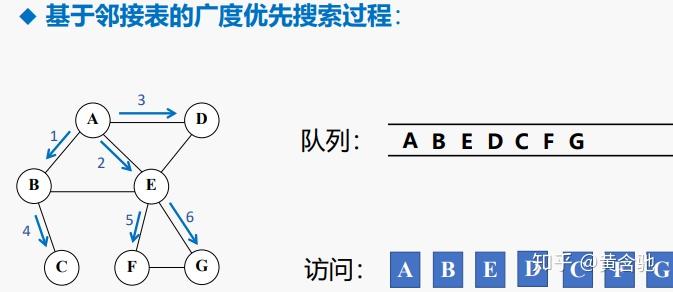




前言
深度优先搜索 的实现是 递归,一直是新手程序员上路的一道坎。记得刚开始学递归的时候,无论怎么看这个代码都觉得不对劲,一直都理解不了,后来通过不断刷题,不断总结,终于有了眉目。有些时候,当你理解不了的时候,最好把图画出来,可能会清晰很多。
广度优先搜索 主要用于求最短路问题。相对来说代码量会比深度优先搜索大一点,但是理解起来稍微容易一些。这里我先用动图的方式简单介绍一下深度优先搜索的原理,如果有兴趣深入了解,可以到文末的知乎专栏中继续阅读。
一、搜索算法的原理
- 搜索算法的原理就是枚举。利用计算机的高性能,给出人类制定好的规则,枚举出所有可行的情况,找到可行解或者最优解。


- 比较常见的搜索算法是 深度优先搜索(又叫深度优先遍历) 和 广度优先搜索(又叫广度优先遍历 或者 宽度优先遍历)。各种图论的算法基本都是依靠这两者进行展开的。
- 深度优先搜索一般用来求可行解,利用剪枝进行优化,在树形结构的图上用处较多;而广度优先搜索一般用来求最优解,配合哈希表进行状态空间的标记,从而避免重复状态的计算;
二、深度优先搜索
1、DFS
1)算法原理
深度优先搜索(Depth First Search),是图遍历算法的一种。用一句话概括就是:“一直往下走,走不通回头,换条路再走,直到无路可走”。具体算法描述为:
选择一个起始点 u 作为 当前结点,执行如下操作:
a. 访问 当前结点,并且标记该结点已被访问,然后跳转到 b;
b. 如果存在一个和 当前结点 相邻并且尚未被访问的结点 v ,则将 v 设为 当前结点,继续执行 a;
c. 如果不存在这样的 v ,则进行回溯,回溯的过程就是回退 当前结点;
- 上述所说的 当前结点 需要用一个栈来维护,每次访问到的结点入栈,回溯的时候出栈。除了栈,另一种实现深度优先搜索的方式是递归,代码更加简单,相对好理解。
【例题1】给定一个 n 个结点的无向图,要求从 0 号结点出发遍历整个图,求输出整个过程的遍历序列。其中,遍历规则为:
1)如果和 当前结点 相邻的结点已经访问过,则不能再访问;
2)每次从和 当前结点 相邻的结点中寻找一个编号最小的没有访问的结点进行访问;
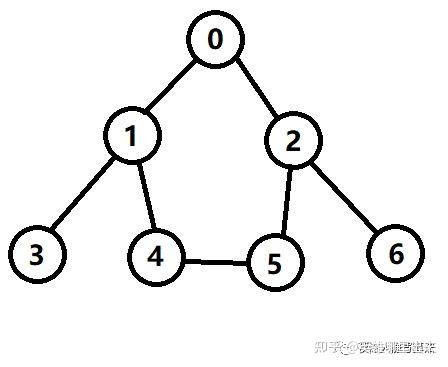

- 如图1所示,对上图以深度优先的方式进行遍历,起点是 0;
- <1> 第一步,当前结点为 0,标记已访问,然后从相邻结点中找到编号最小的且没有访问的结点 1;
- <2> 第二步,当前结点为 1,标记已访问,然后从相邻结点中找到编号最小的且没有访问的结点 3;
- <3> 第三步,当前结点为 3,标记已访问,没有尚未访问的相邻结点,执行回溯,回到结点 1;
- <4> 第四步,当前结点为 1,从相邻结点中找到编号最小的且没有访问的结点 4;
- <5> 第五步,当前结点为 4,标记已访问,然后从相邻结点中找到编号最小的且没有访问的结点 5;
- <6> 第六步,当前结点为 5,标记已访问,然后从相邻结点中找到编号最小的且没有访问的结点 2;
- <7> 第七步,当前结点为 2,标记已访问,然后从相邻结点中找到编号最小的且没有访问的结点 6;
- <8> 第八步,当前结点为 6,标记已访问,没有尚未访问的相邻结点,执行回溯,回到结点 2;
- <9> 第九步,按照 2 => 5 => 4 => 1 => 0 的顺序一路回溯,搜索结束;
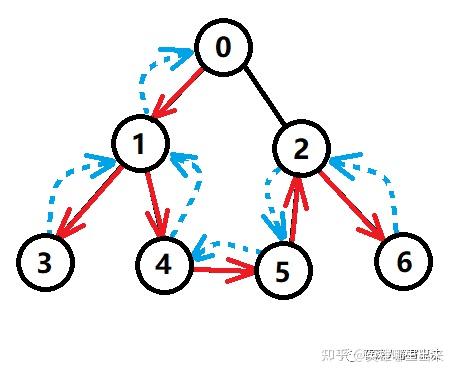

- 如下图所示,红色实箭头表示搜索路径,蓝色虚箭头表示回溯路径。
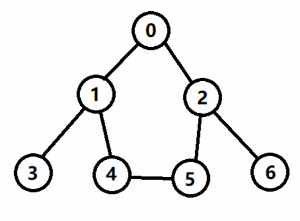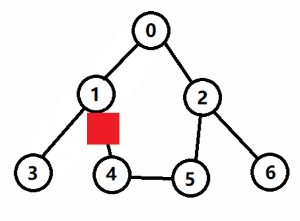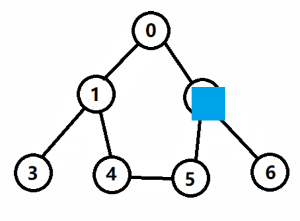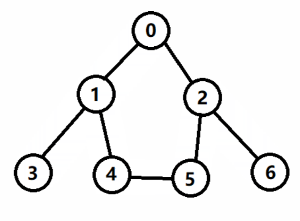
- 图中,红色块表示往下搜索,蓝色块表示往上回溯,遍历序列为:
0 -> 1 -> 3 -> 4 -> 5 -> 2 -> 6
2)算法实现
const int MAXN = 7;
void dfs(int u) {
if(visit[u]) { // 1
return ;
}
visit[u] = true; // 2
dfs_add(u); // 3
for(int i = 0; i < MAXN; ++i) {
int v = i;
if(adj[u][v]) { // 4
dfs(v); // 5
}
}
}
- 1、
visit[MAXN]数组是一个bool数组,用于标记某个节点是否已访问,初始化都为 false;这里对已访问结点执行回溯; - 2、
visit[u] = true;对未访问结点 u 标记为已访问状态; - 3、
dfs_add(u);用来将 u 存储到的访问序列中,实际函数实现如下:
void dfs_add(int u) {
ans[ansSize++] = u;
}
- 4、
adj[MAXN][MAXN]是图的邻接矩阵,用 0 或 1 来代表点是否连通,对于上面的例子,邻接矩阵表示如下:
bool adj[MAXN][MAXN] = {
{0, 1, 1, 0, 0, 0, 0},
{1, 0, 0, 1, 1, 0, 0},
{1, 0, 0, 0, 0, 1, 1},
{0, 1, 0, 0, 0, 0, 0},
{0, 1, 0, 0, 0, 1, 0},
{0, 0, 1, 0, 1, 0, 0},
{0, 0, 1, 0, 0, 0, 0},
};
(adj[u][v] = 1代表 u 和 v 之间有一条有向边;adj[u][v] = 0代表没有边)
- 5、递归调用相邻结点;
3)基础应用
a. 求阶乘
【例题2】给出 n ( n \le 10 ) ,求 n! = n*(n-1)...3*2*1 ; 令 f(n) = n! ,那么有 f(n) = n * f(n-1) (n>0) 。由于满足递归的性质,可以认为这是一个 n+1 个结点的图,结点 i (i \ge 1) 到结点 i-1 有一条权值为 i 的有向边,从 n 开始进行深度优先搜索,搜索的终点是结点 0 ,返回值为 1 (即 0! = 1 )。


- 如图所示, n! 的递归计算看成是一个 深度优先搜索 的过程,红色路径代表递归往下搜索,蓝色路径代表回溯,并且每次回溯的时候会将遍历的结果返回给上一个结点(当然,这只是一个思想,并不代表这是求 n! 的高效算法)。
- C++ 代码实现如下:
int dfs(int n) {
return !n ? 1 : n * dfs(n-1);
}
- 由于 C++ 中的 int 是 32 位整数,最大能够表示的值为 2^{31}-1 ,所以这里的 n 太大就会导致溢出,需要用数组来模拟实现高精度。
b. 求斐波那契数列的第n项
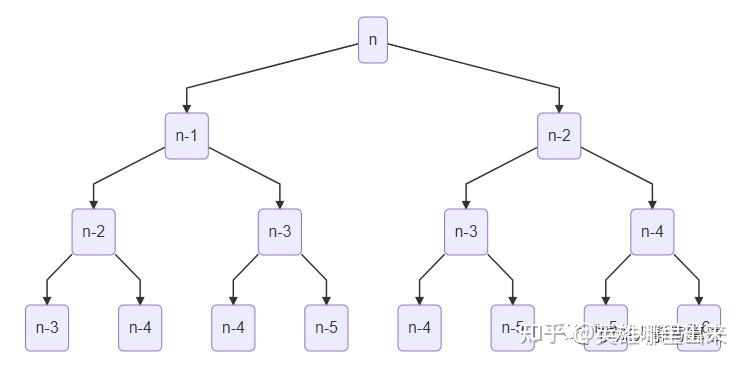
【例题3】令 g(n) = g(n-1) + g(n-2) , (1 < n < 40) ,其中 g(0) = g(1) = 1 ;
同样可以利用图论的思想,从结点 n 向 n-1 和 n-2 分别引一条权值为 1 的有向边,每次求 g(n) 就是以 n 作为起点,对 n 进行深度优先搜索,然后将 n -1 和 n-2 回溯的结果相加作为 n 结点的值,即 g(n) 。

- C++ 代码实现如下:
int dfs(unsigned int n) {
if(n <= 1) {
return 1;
}
return dfs(n-1) + dfs(n-2);
}
- 例如, g(5) 的计算流程如图所示:

- 这里会带来一个问题, g(n) 的计算需要用到 g(n-1) 和 g(n-2) ,而 g(n-1) 的计算需要用到 g(n-2) 和 g(n-3) ,所以我们发现 g(n-2) 被用到了两次,而且每个结点都存在这个问题,这样就使得整个算法的时间复杂度变成指数级了,对于斐波那契数列递归算法的时间复杂度分析,可以参考这篇文章: 斐波那契数列递归时间复杂度分析
- 为了规避这个问题,下面会讲到基于深搜的记忆化搜索。
c. 求 n 个数的全排列
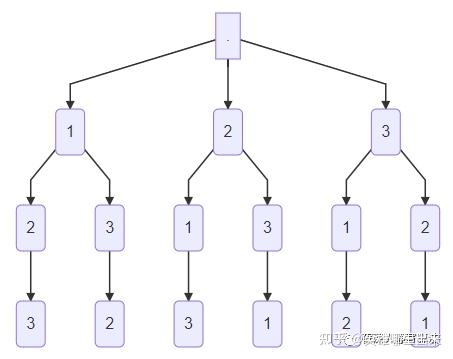
【例题4】给定 n , 按字典序输出 1 到 n 的所有全排列;
全排列的种数是 n! ,要求按照字典序输出。这是最典型的深搜问题。我们可以把 n 个数两两建立无向边(即任意两个结点之间都有边,也就是一个 n 个结点的完全图),然后对每个点作为起点,分别做一次深度优先搜索,当所有点都已经标记时,输出当前的搜索路径,就是其中一个排列;
这里需要注意的是,回溯的时候需要将原先标记的点的标记取消,否则只能输出一个排列。如果要按照字典序,则需要在遍历的时候保证每次遍历都是按照结点从小到大的方式进行遍历的。
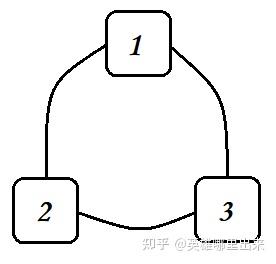
- 如下图所示,代表了一个 3个数的全排列的深度优先搜索空间树;

- C++ 代码实现如下:
void dfs(int depth) { // 1
if(depth == MAXN) { // 2
dfs_print();
return;
}
for(int i = 1; i <= MAXN; ++i) {
int v = i;
if(!visit[v]) { // 3
dfs_add(v); // 4
dfs(depth+1);
dfs_dec(v);
}
}
}
- 1)这里的
depth参数用来做计数用,表明本次遍历了多少个结点; - 2)当遍历元素达到
MAXN个的时候,输出访问的元素列表; - 3)
visit[v]用来判断 v 这个元素是否有访问过; - 4)
dfs_add和dfs_dec分别表示将结点从访问列表加入和删除;
void dfs_add(int u) {
visit[u] = true;
ans[ansSize] = u;
++ansSize;
}
void dfs_dec(int u) {
--ansSize;
visit[u] = false;
}
4)高级应用
a. 枚举 数据范围较小的的排列、组合的穷举。
b. 容斥原理 主要用于组合数学中的计数统计,会在后面的章节详细介绍。
c. 基于状态压缩的动态规划 一般解决棋盘摆放问题,k 进制表示状态,然后利用深搜进行状态转移,会在后面的章节详细介绍。
d.记忆化搜索 某个状态已经被计算出来,就将它 cache 住,利用数组或者哈希表将它的值存储下来,下次要用的时候不需要重新求,此所谓记忆化。
e.有向图强连通分量 经典的 Tarjan 算法,求解 2-sat 问题的基础,会在后面的章节详细介绍。
f. 无向图割边割点和双连通分量 经典的 Tarjan 算法,会在后面的章节详细介绍。
g. LCA 最近公共祖先 最近公共祖先递归求解,会在后面的章节详细介绍。
h.博弈 利用深搜计算SG值,会在后面的章节详细介绍。
i.二分图最大匹配 经典的匈牙利算法,最小顶点覆盖、最大独立集、最小值支配集 向二分图的转化,会在后面的章节详细介绍。
j.欧拉回路 经典的圈套圈算法,会在后面的章节详细介绍。
k.K短路 依赖数据,数据不卡的话可以采用2分答案 + 深搜;也可以用广搜 + A。
l. 线段树 二分经典思想,配合深搜枚举左右子树,求和、最值等问题,会在后面的章节详细介绍。
m. 最大团 极大完全子图的优化算法,会在后面的章节详细介绍。
n. 最大流 EK算法求任意路径中有涉及,会在后面的章节详细介绍。
o. 树形DP 即树形动态规划,父结点的值由各个子结点计算得出,会在后面的章节详细介绍。
- 以上是对「 深度优先搜索 」 的简介,如果有兴趣,可以仔细阅读我知乎专栏 「 夜深人静写算法 」的文章

为了便于描述,本文中的图指的是下图所示的无向图。
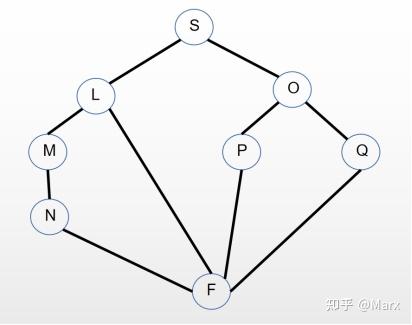
搜索指:搜索从S到F的一条路径。若存在,则以表的形式返回路径;若不存在,则返回nil。
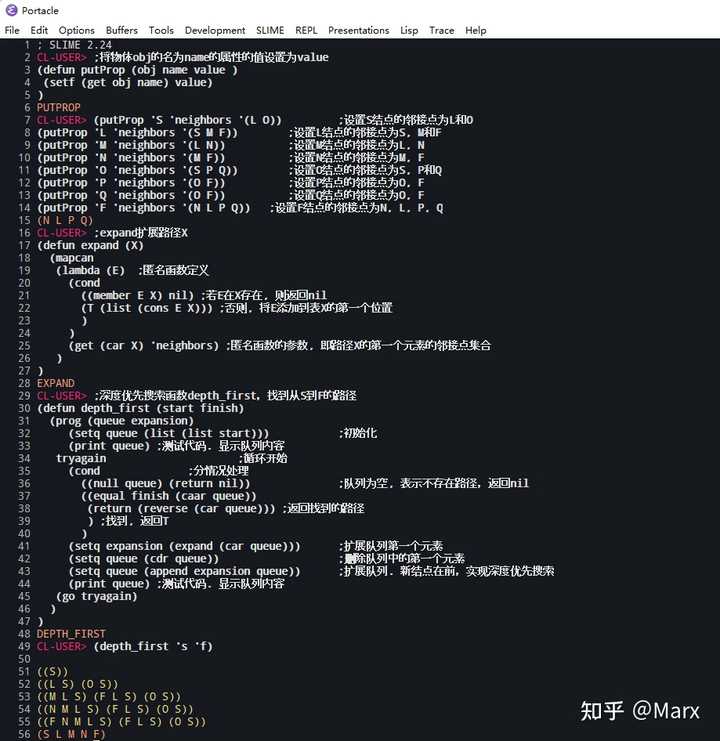
定义属性设置函数putProp
;将物体obj的名为name的属性的值设置为value
(defun putProp (obj name value )
(setf (get obj name) value)
)
;测试函数putProp的代码
(putprop 'James 'son '(robert albert) )
(get 'James 'son)
图的表示
使用原子和特性表来表示上图中各结点之间的邻接关系。代码如下:
(putProp 'S 'neighbors '(L O)) ;设置S结点的邻接点为L和O
(putProp 'L 'neighbors '(S M F)) ;设置L结点的邻接点为S, M和F
(putProp 'M 'neighbors '(L N)) ;设置M结点的邻接点为L, N
(putProp 'N 'neighbors '(M F)) ;设置N结点的邻接点为M, F
(putProp 'O 'neighbors '(S P Q)) ;设置O结点的邻接点为S, P和Q
(putProp 'P 'neighbors '(O F)) ;设置P结点的邻接点为O, F
(putProp 'Q 'neighbors '(O F)) ;设置Q结点的邻接点为O, F
(putProp 'F 'neighbors '(N L P Q)) ;设置F结点的邻接点为N, L, P, Q
定义路径扩展函数expand
路径扩展函数,将路径X的第一个元素(即图中的某个结点)的邻接点集合E加入到X中(若E已经在X中,则不加入;这样是为了消除闭合路径)。代码如下:
;expand扩展路径X
(defun expand (X)
(mapcan
(lambda (E) ;匿名函数定义
(cond
((member E X) nil) ;若E在X存在, 则返回nil
(T (list (cons E X))) ;否则, 将E添加到表X的第一个位置
)
)
(get (car X) 'neighbors) ;匿名函数的参数, 即路径X的第一个元素的邻接点集合
)
)
上述的cond子句中,如果路径是闭合路径,则返回nil,append抛弃nil项;将非nil项收集到一张表中,作为expand的返回值。
深度优先搜索函数depth_first
函数代码如下
;深度优先搜索函数depth_first,找到从S到F的路径
(defun depth_first (start finish)
(prog (queue expansion)
(setq queue (list (list start))) ;初始化
(print queue) ;测试代码. 显示队列内容
tryagain ;循环开始
(cond ;分情况处理
((null queue) (return nil)) ;队列为空, 表示不存在路径,返回nil
((equal finish (caar queue))
(return (reverse (car queue))) ;返回找到的路径
) ;找到, 返回T
)
(setq expansion (expand (car queue))) ;扩展队列第一个元素
(setq queue (cdr queue)) ;删除队列中的第一个元素
(setq queue (append expansion queue)) ;扩展队列. 新结点在前,实现深度优先搜索
(print queue) ;测试代码. 显示队列内容
(go tryagain)
)
)
函数的运行及结果:
(depth_first 's 'f) ;lisp不区分符号的大小写
运行结果为输出(S L M N F)。

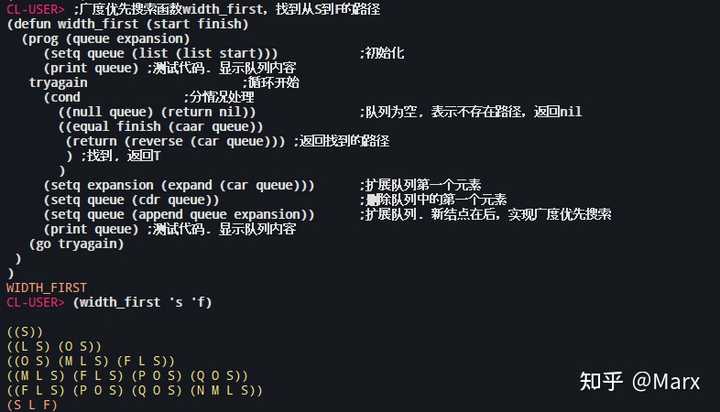
广度优先搜索函数width_first
广度优先与深度优先的代码基本一致,只有代码“(setq queue (append queue expansion))”不同,广度优先将expansion放在队尾,深度优先将expansion放在队首。函数代码如下:
;广度优先搜索函数width_first,找到从S到F的路径
(defun width_first (start finish)
(prog (queue expansion)
(setq queue (list (list start))) ;初始化
(print queue) ;测试代码. 显示队列内容
tryagain ;循环开始
(cond ;分情况处理
((null queue) (return nil)) ;队列为空, 表示不存在路径,返回nil
((equal finish (caar queue))
(return (reverse (car queue))) ;返回找到的路径
) ;找到, 返回T
)
(setq expansion (expand (car queue))) ;扩展队列第一个元素
(setq queue (cdr queue)) ;删除队列中的第一个元素
(setq queue (append queue expansion)) ;扩展队列. 新结点在后,实现广度优先搜索
(print queue) ;测试代码. 显示队列内容
(go tryagain)
)
)
函数的运行及结果:
(width_first 's 'f) ;lisp不区分符号的大小写
运行结果为输出(S L F)。


在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某 个顶点与指定顶点是否相通,是非常常见的需求。 有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法。
一、深度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找子结点,然后找 兄弟结点。
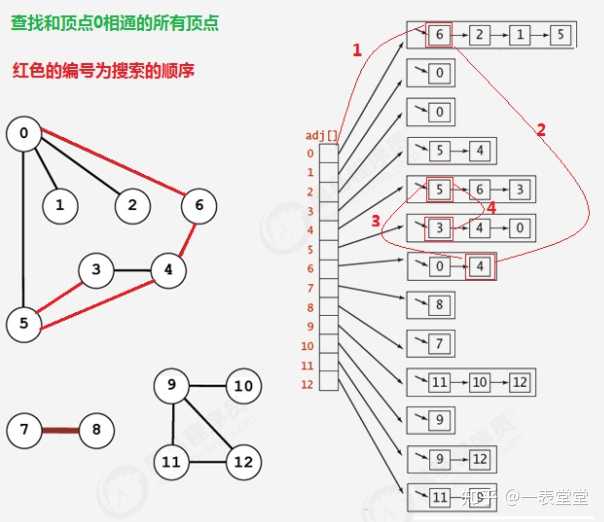

很明显,在由于边是没有方向的,所以,如果4和5顶点相连,那么4会出现在5的相邻链表中,5也会出现在4的相 邻链表中,那么为了不对顶点进行重复搜索,应该要有相应的标记来表示当前顶点有没有搜索过,可以使用一个布 尔类型的数组 boolean[V] marked,索引代表顶点,值代表当前顶点是否已经搜索,如果已经搜索,标记为true, 如果没有搜索,标记为false;
API设计:


代码:
public class DepthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相邻顶点
public DepthFirstSearch(Graph G,int s){
//创建一个和图的顶点数一样大小的布尔数组 marked = new boolean[G.V()];
//搜索G图中与顶点s相同的所有顶点 dfs(G,s); }
//使用深度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G, int v){ //把当前顶点标记为已搜索 marked[v]=true;
//遍历v顶点的邻接表,得到每一个顶点w for (Integer w : G.adj(v)){
//如果当前顶点w没有被搜索过,则递归搜索与w顶点相通的其他顶点
if (!marked[w]){ dfs(G,w); } }//相通的顶点数量+1 count++; }//判断w顶点与s顶点是否相通
public boolean marked(int w){ return marked[w]; }//获取与顶点s相通的所有顶点的总数
public int count(){ return count; } }二、广度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找兄弟结点,然后 找子结点。
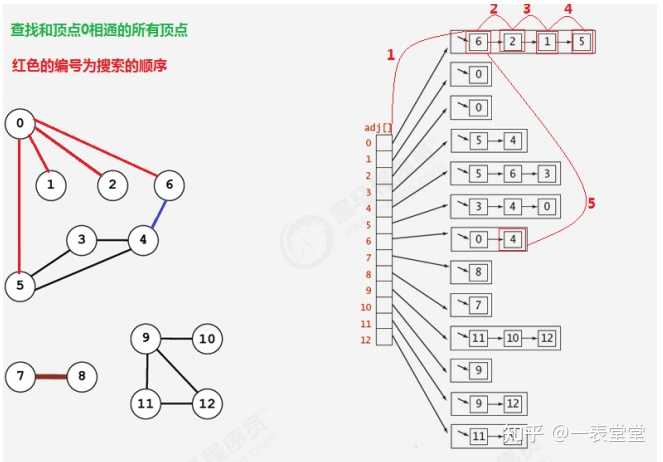

API设计:


代码:
public class BreadthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//用来存储待搜索邻接表的点 private Queue<Integer> waitSearch; 12345678
//构造广度优先搜索对象,使用广度优先搜索找出G图中s顶点的所有相邻顶点
public BreadthFirstSearch(Graph G, int s) {
//创建一个和图的顶点数一样大小的布尔数组
marked = new boolean[G.V()];
//初始化待搜索顶点的队列
waitSearch = new Queue<Integer>();
//搜索G图中与顶点s相同的所有顶点
dfs(G, s); }
//使用广度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G, int v) {
//把当前顶点v标记为已搜索
marked[v]=true;
//把当前顶点v放入到队列中,等待搜索它的邻接表
waitSearch.enqueue(v);
//使用while循环从队列中拿出待搜索的顶点wait,进行搜索邻接表
while(!waitSearch.isEmpty()){ Integer wait = waitSearch.dequeue();
//遍历wait顶点的邻接表,得到每一个顶点w for (Integer w : G.adj(wait)) { //如果当前顶点w没有被搜索过,则递归搜索与w顶点相通的其他顶点 if (!marked[w]) { dfs(G, w); } } }//相通的顶点数量+1 count++; }//判断w顶点与s顶点是否相通 public boolean marked(int w) { return marked[w]; }//获取与顶点s相通的所有顶点的总数 public int count() { return count; } }三、案例-畅通工程续1
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。目前的道路状况,9号城市和10号城市是否相通?9号城市和8号城市是否相通?
在我们的测试数据文件夹中有一个trffiffiffic_project.txt文件,它就是诚征道路统计表,下面是对数据的解释:
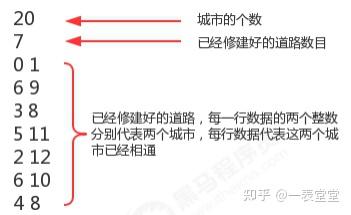
总共有20个城市,目前已经修改好了7条道路,问9号城市和10号城市是否相通?9号城市和8号城市是否相通?
解题思路:
1.创建一个图Graph对象,表示城市;
2.分别调用
addEdge(0,1),addEdge(6,9),addEdge(3,8),addEdge(5,11),addEdge(2,12),addEdge(6,10),addEdge(4,8),表示已经修建好的道路把对应的城市连接起来;
3.通过Graph对象和顶点9,构建DepthFirstSearch对象或BreadthFirstSearch对象;
4.调用搜索对象的marked(10)方法和marked(8)方法,即可得到9和城市与10号城市以及9号城市与8号城市是否相通。
代码:
本文是Java数据结构与算法教程的课件文档,获取学习最新全套 java数据结构算法, 左神算法大厂LeetCode刷题教程请点击即可获取。


1.迭代加深
深度优先搜索每次选定一个分支,不断深入直到递归边界才回溯.当搜索树的分支特别多,但答案处于较浅层的节点上,就会导致浪费许多时间.
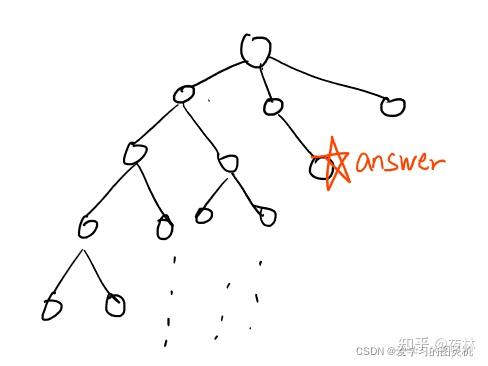
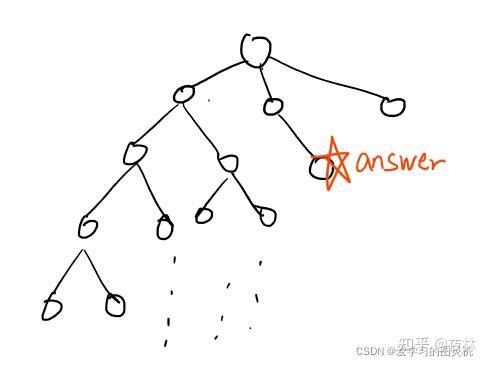
所以我们通过指定搜索的最大深度,逐步加深,保证递归层数不大.
这种方法确实会重复搜索浅层节点,但是前层的节点数量之和在最坏情况下等于第层节点数 - 1(满二叉树),分支增多则小于最后一层节点数,故总数量级仍为最后一层节点数,可以接受.
这个算法需要保证答案在浅层节点,有些题目里面会有相应的提示,比如"如果10步以内搜不到答案就算无解 "此类.
AdditionChains
满足如下条件的序列 X(序列中元素被标号为 1、2、3…m)被称为“加成序列”:
X[1]=1
X[m]=n
X[1]<X[2]<…<X[m−1]<X[m]
对于每个 k(2≤k≤m)都存在两个整数 i 和 j (1≤i,j≤k−1,i 和 j 可相等),使得 X[k]=X[i]+X[j]。
你的任务是:给定一个整数 n,找出符合上述条件的长度 m 最小的“加成序列”。
如果有多个满足要求的答案,只需要找出任意一个可行解。 n <= 100
在最坏情况下,时要搜100层,但是在较好的情况下,由于满足,i 和 j 可相等,故可以每次翻倍,,8层就能搜到答案.所以答案的层数应该不深.迭代加深搜索,
这里有两个剪枝的技巧:
1.由于要满足,i和j我们从大到小枚举,优先选择较大的数可以使得后续的分支较少,让我们更快搜到答案.(顺序)
2.假设现在序列为1,2,3,4,第5位可以取5 = 1 + 4 = 2 + 3,会有冗余搜索,开一个st数组判断当前数(5)有没有被枚举过,若枚举过就不在dfs一层,因为之前已经dfs过了.
代码
/*
* @Author: ACCXavier
* @Date: 2022-01-28 22:29:01
* @LastEditTime: 2022-01-29 09:20:03
* Bilibili:https://space.bilibili.com/7469540
* @keywords: DFS迭代加深
* 逐步增加搜索层数
*/
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 110;
int path[N];
int n;
//当前层,要搜到的层(从1开始的)
bool dfs(int u,int depth){
if(u == depth){
return path[u - 1] == n;
}
bool st[N] = {0};
for(int i = u - 1; i >= 0; -- i){
for(int j = i; j >= 0; -- j){//j > i组合搜索
int s = path[i] + path[j];
//保证严格单调递增
if(s > n || s <= path[u - 1] || st[s])continue;
st[s] = true;
path[u] = s;
if(dfs(u + 1,depth))return true;
}
}
return false;
}
int main()
{
path[0] = 1;
while(cin >> n,n){
int depth = 1;
while(!dfs(1,depth)) ++ depth;//false说明层数不够
for(int i = 0; i < depth; ++ i)cout << path[i] << ' ';
cout << endl;
}
}
2.IDA*
dfs有两种分类.1是在图上进行寻找广义最短路,称之为内部搜索,例如 迷宫;另一种是将一个图设为一个状态,每次操作对整个图进行变换,寻找最短的变换次数,称之为外部搜索,例如 八数码,.
IDA*是一种基于迭代加深的启发式算法,一般是对外部搜索问题进行处理.对从初始状态操作到对应的操作步数为,我们要算估价函数,是我们估计的到目标状态的操作距离,这个操作距离在dfs中就是搜索层数.
估价函数性质:要保证到终态的距离.等号一般只在已经到达终态时成立 作用:能够剪枝.找广义最小距离时,当当前距离时,则直接return.因为,继续搜不可能找到距离更小的路.
简单的说就是我们开一个估计函数这个估计函数的返回值小于等于真实值这样我们就可以利用这个进行最优化减枝 如果估计函数都无法完成那么真实值一定也无法完成可以直接剪掉
Booksort
给定 n 本书,编号为 1∼n。
在初始状态下,书是任意排列的。
在每一次操作中,可以抽取其中连续的一段,再把这段插入到其他某个位置。
我们的目标状态是把书按照 1∼n 的顺序依次排列。
求最少需要多少次操作。
如果最少操作次数大于或等于 **5** 次,则输出 5 or more。
本题可以详细的估算暴搜的复杂度 计数每次将本书移动的所有情况次数


暴力搜索,使用IDA*,估价函数的取法及原理如下
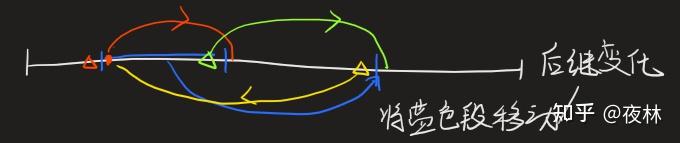

图中蓝色段为要挪动的书,挪动位置标出,这次挪动改变了三个元素的后继元素,分别用红,绿,蓝标出了后继的改变.
也就是说一次挪动改变3个后继,设总共不正确后继为,则最少需要操作次,将其设为估价函数
代码
/*
* @Author: ACCXavier
* @Date: 2022-01-30 19:51:40
* @LastEditTime: 2022-01-30 21:01:19
* Bilibili:https://space.bilibili.com/7469540
* @keywords: DFS 中等
我们开一个估计函数这个估计函数的返回值小于等于真实值这样我们就可以利用这个进行最优化减枝
如果估计函数都无法完成那么真实值一定也无法完成可以直接剪掉
由于步数很小答案可能会很大所以用迭代加深优化搜索
枚举选择的长度以及放的位置
选择书后不用往前放,因为会对应前面的一种选法,重复
这题由于每次我们最多改变3个后继的位置的关系所以假设我们有tot个错误前后关系那么(tot+2)/3就是我们最多要操作的次数
我们可以用这个(tot+2)/3来当成估计函数
*/
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 15;
int q[N];
int w[5][N];//暂存每层u的状态
int n;
int f(){//不正确的后继数量
int cnt = 0;
for(int i = 0; i < n - 1; ++ i){
if(q[i + 1] != q[i] + 1)cnt ++;
}
return (cnt + 2)/3;//对3上取整
}
bool dfs(int u,int depth){
if(u + f() > depth)return false;//
if(!f())return true;//为0表示已经排好
for(int len = 1; len <= n; ++ len){//移动len长度的书
for(int l = 0; l + len - 1 < n; ++ l){//左端点从0开始,右端点就要-1
int r = l + len - 1;
for(int k = r + 1; k < n; ++ k){//移动到第k位数字的后面,从r + 1位开始
//memcpy(str1, str2, size_t n) 从存储区 str2 复制 n 个字节到存储区 str1。
memcpy(w[u],q,sizeof q);//暂时存储
int x,y;
//y x
//l______r____k____
for(x = r + 1,y = l;x <= k;x ++,y ++)q[y] = w[u][x];
//再拷贝前面的一部分,y继续加
for(x = l; x <= r; ++ x, ++ y)q[y] = w[u][x];
if(dfs(u + 1,depth))return true;
memcpy(q,w[u],sizeof q);//回溯
}
}
}
return false;//! bool类型默认返回值true,很容易造成搜索结果错误!
//!除了void,都记得写return!
}
int main()
{
int T;
cin >> T;
while(T --){
cin >> n;
for(int i = 0; i < n; ++ i){
cin >> q[i];
}
int depth = 0;//0次对应已经排好序
while(depth < 5 && !dfs(0,depth))depth ++;
if(depth == 5)puts("5 or more");
else printf("%d\n",depth);
}
return 0;
}
TheRotationGame
如下图所示,有一个 # 形的棋盘,上面有 1,2,3 三种数字各 8 个。
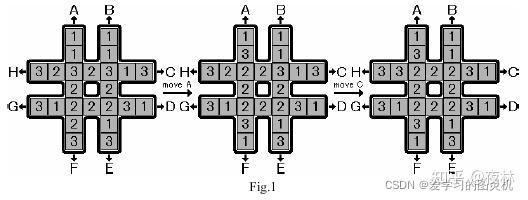

给定 8 种操作,分别为图中的 A∼H。
这些操作会按照图中字母和箭头所指明的方向,把一条长为 7 的序列循环移动 1 个单位。
例如下图最左边的 # 形棋盘执行操作 A 后,会变为下图中间的 # 形棋盘,再执行操作 C 后会变成下图最右边的 # 形棋盘。
给定一个初始状态,请使用最少的操作次数,使 # 形棋盘最中间的 8 个格子里的数字相同。
输入格式 输入包含多组测试用例。 每个测试用例占一行,包含 24 个数字,表示将初始棋盘中的每一个位置的数字,按整体从上到下,同行从左到右的顺序依次列出。 输入样例中的第一个测试用例,对应上图最左边棋盘的初始状态。 当输入只包含一个 0 的行时,表示输入终止。 输出格式 每个测试用例输出占两行。 第一行包含所有移动步骤,每步移动用大写字母 A∼H 中的一个表示,字母之间没有空格,如果不需要移动则输出 No moves needed。 第二行包含一个整数,表示移动完成后,中间 8 个格子里的数字。
如果有多种方案,则输出字典序最小的解决方案。 输入样例:
1 1 1 1 3 2 3 2 3 1 3 2 2 3 1 2 2 2 3 1 2 1 3 3
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3
0
输出样例:
AC
2
DDHH
2
一样用IDA*,此时估价函数为中间格最多数字的个数.因为每次对一条操作能改变中间8格的一格(看起来是改了两格,但数字只变化了一个),故,可以用.
代码
/*
* @Author: ACCXavier
* @Date: 2022-01-30 20:12:57
* @LastEditTime: 2022-01-31 10:50:48
* Bilibili:https://space.bilibili.com/7469540
* @keywords: DFS 中等
*
*/
/*
0 1
0 1
2 3
7 4 5 6 7 8 9 10 2
11 12
6 13 14 15 16 17 18 19 3
20 21
22 23
5 4
*/
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 24;
//如果op里面用从1开始的编号,那么opposite和center也改成从1开始,q从1输入即可
int op[8][7] = {
{0, 2, 6, 11, 15, 20, 22},
{1, 3, 8, 12, 17, 21, 23},
{10, 9, 8, 7, 6, 5, 4},
{19, 18, 17, 16, 15, 14, 13},
{23, 21, 17, 12, 8, 3, 1},
{22, 20, 15, 11, 6, 2, 0},
{13, 14, 15, 16, 17, 18, 19},
{4, 5, 6, 7, 8, 9, 10}
};
int opposite[8] = {5, 4, 7, 6, 1, 0, 3, 2};
int center[8] = {6, 7, 8, 11, 12, 15, 16, 17};
int q[N];
int path[100];
int f()//8 - cnt(最多的数字),<=最小操作步数
{
static int sum[4];
memset(sum, 0, sizeof sum);
for (int i = 0; i < 8; i ++ ) sum[q[center[i]]] ++ ;
int maxv = 0;
for (int i = 1; i <= 3; i ++ ) maxv = max(maxv, sum[i]);
return 8 - maxv;//!8 - maxv,距离
}
void operate(int x)//操作第x个条
{
int t = q[op[x][0]];//正方向第一个
for (int i = 0; i < 6; i ++ ) q[op[x][i]] = q[op[x][i + 1]];//循环
q[op[x][6]] = t;//最后一位
}
//当前第u层,上限depth,最后一个操作的编号
bool dfs(int u, int depth, int last)
{
if (u + f() > depth) return false;
if (f() == 0) return true;
for (int i = 0; i < 8; i ++ )
if (last != opposite[i])//不能做上一步操作的逆操作,无用功
{
operate(i);
path[u] = i;
if (dfs(u + 1, depth, i)) return true;
operate(opposite[i]);//回溯
}
return false;
}
int main()
{
while (cin >> q[0], q[0])
{
for (int i = 1; i < 24; i ++ ) cin >> q[i];
int depth = 0;
while (!dfs(0, depth, -1)) depth ++ ;
if (!depth) printf("No moves needed");
else
{
for (int i = 0; i < depth; i ++ ) printf("%c", 'A' + path[i]);
}
printf("\n%d\n", q[6]);
}
return 0;
}
3.双向DFS
从两个方向搜索,搜索树会变小.如图

送礼物
达达帮翰翰给女生送礼物,翰翰一共准备了 N 个礼物,其中第 i 个礼物的重量是 G[i]。
达达的力气很大,他一次可以搬动重量之和不超过 W 的任意多个物品。
达达希望一次搬掉尽量重的一些物品,请你告诉达达在他的力气范围内一次性能搬动的最大重量是多少。
输入格式 第一行两个整数,分别代表 W 和 N。
以后 N 行,每行一个正整数表示 G[i]。
输出格式 仅一个整数,表示达达在他的力气范围内一次性能搬动的最大重量。
数据范围 输入样例:
20 5
7
5
4
18
1输出样例:
19是个背包问题,但是物品质量太大,以背包的复杂度无法处理。故本题先预处理搜一部分所有的物品组合情况,再暴搜后一部分。
后一部分搜出权重后,在前面寻找最大的使得,前部分暴搜后排序,即可用二分。前后搜相当于两个方向dfs。 时间复杂度详细分析如下,先尝试对半分:


恰当的选区分界点可以降低搜索计算量,本题选,注意当时要特判.
代码
/*
* @Author: ACCXavier
* @Date: 2022-01-29 16:26:07
* @LastEditTime: 2022-01-29 17:07:40
* Bilibili:https://space.bilibili.com/7469540
* @keywords: 双向DFS
* 将物品分两份,前一部分k暴搜出所有方案,再搜后一部分二分<=m的最大值
*/
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long ll;
const int N = 46;
int n,m;//物品数量和承受重量
int w[N];//每件物品的质量
int k;//前一部分k个
int weight[1 << 25],//前k部分的所有方案
cnt = 1;//已有一种方案,即不选,放在0位,后续搜索的时候都是不选就是只选前半部分,前面也不选那就是全不选
int ans;
//物品序号(从0开始),当前质量和
void dfs1(int u,int s){
if(u == k){//从0开始,所以u == k表示已经处理了0~u-1共k个物品
//!搜到k 不是 n
weight[cnt ++ ] = s;
return;
}
if((ll)s + w[u] <= m)dfs1(u + 1,s + w[u]);
dfs1(u + 1,w1);
}
//物品序号(从0开始),当前质量和
void dfs2(int u,int s){
if(u >= n){//写>是因为k若取n/2+2可能大于n,等同于边界特判
//找<=m的最大数,前驱
int l = 0,r = cnt - 1;
while(l < r){
int mid = l + r + 1 >> 1;
if((ll)sum + weight[mid] <= m)l = mid;
else r = mid - 1;
}
ans = max(ans,sum + weight[l]);
return;
}
dfs2(u + 1,sum);
if((ll)sum + w[u] <= m)dfs2(u + 1,sum + w[u]);
}
int main(){
cin >> m >> n;
for(int i = 0; i < n; ++ i){
cin >> w[i];
}
sort(w,w + n,greater<int>());
k = n / 2 + 2;
dfs1(0,0);
//!只需要排序到cnt
sort(weight,weight + cnt);//二分要用weight,不要倒序排序
cnt = unique(weight,weight + cnt) - weight;
dfs2(k,0);
cout << ans << endl;
return 0;
}

给定一个有向图,一个源顶点s和一个目标顶点d,输出从给定's'到'd'的所有路径,这是一个基本的图遍历问题,可以基于深度优先(DFS)或者广度优先(BFS)策略实现。但是目前网上的代码,基本都是基于C++,Java,C#等语言实现,尚未找到R语言实现。因此,本文利用R语言,实现基于DFS的路径遍历算法。
(1)定义图的初始化函数,用于构建n个节点的图Graph_init
Graph_init <- function( glenth)
{
v = glenth
adjList <- vector("list", length = v) #生成一个出发顶点出发的所有路径列表
for ( i in 1:v) {
adjList[[i]] =list( ) #单个元素列表为该顶点出发的一条路径
}
return(list(adjList = adjList,v =v))
}(2)定义图的添加边函数add_edge
add_edge <- function(adjList,u,v)
{
adjList[[u]]=c(adjList[[u]],v)
return (adjList)
}(3) 定义节点u到节点d的路径查找递归函数printAllPathsUtil
printAllPathsUtil <- function( u, d, isVisited,localPathList,adjList )
{
if (u == d) {
tnodes= unlist(localPathList)
print(tnodes)
}
}
#Mark the current node
isVisited[u] = 1
#Recur for all the vertices
#adjacent to current vertex
for ( i in adjList[[u]]) {
if (isVisited[i]==0) {
localPathList = c(localPathList,i)
printAllPathsUtil(i, d, isVisited, localPathList,adjList)
#remove current node
# in path[]
localPathList = localPathList[-length(localPathList)]
}
}
#Mark the current node
isVisited[u] = 0
}(4)定义打印节点s到d的所有路径 函数printAllPaths
printAllPaths <- function( s, d, v, adjList )
{
isVisited = array(data=0,dim=v)
pathList = list()
# add source to path[]
pathList = c(pathList,s)
#Call recursive utility
rnum = printAllPathsUtil(s, d, isVisited, pathList,adjList )
}(5)定义主函数
dfs_main <- function ()
{
g = Graph_init(4)
adjList = g$adjList
v= g$v
adjList = add_edge(adjList,1, 2)
adjList = add_edge(adjList,1, 3)
adjList = add_edge(adjList,1, 4)
adjList = add_edge(adjList,3, 1)
adjList = add_edge(adjList,3, 2)
adjList = add_edge(adjList,2, 4)
#arbitrary source
s = 3
#arbitrary destination
d = 4
print(paste0("Following are all different paths from ",s," to ",d) )
printAllPaths(s, d, v,adjList)
}输出如下:

