有免费的网络爬虫软件使用吗?
67 个回答

最近我们在做类似的工作,一方面接单独的定制需求,另一方面做一个无需编程的智能云爬虫网站。
可以来我们这里看看: 造数 - 最好用的云爬虫工具
我们精心制作了视频: 造数云爬虫使用教程
--------------------------------------------------------------
因为刚开始三周左右,还有很多项目需要大家的意见来完善。
我们现在可以满足的范例如下:
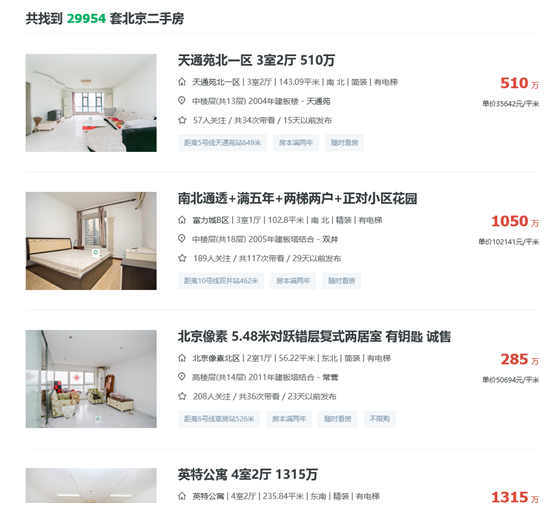

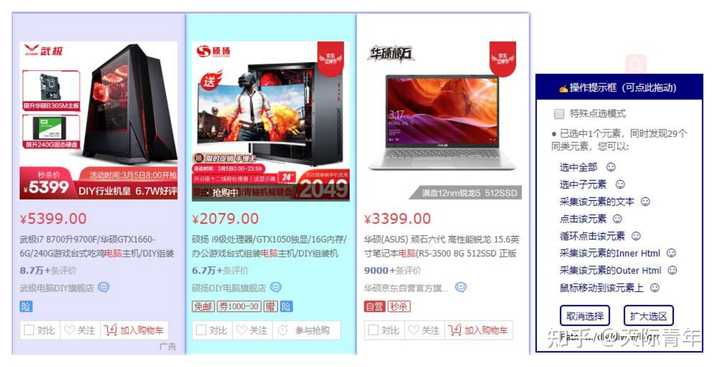
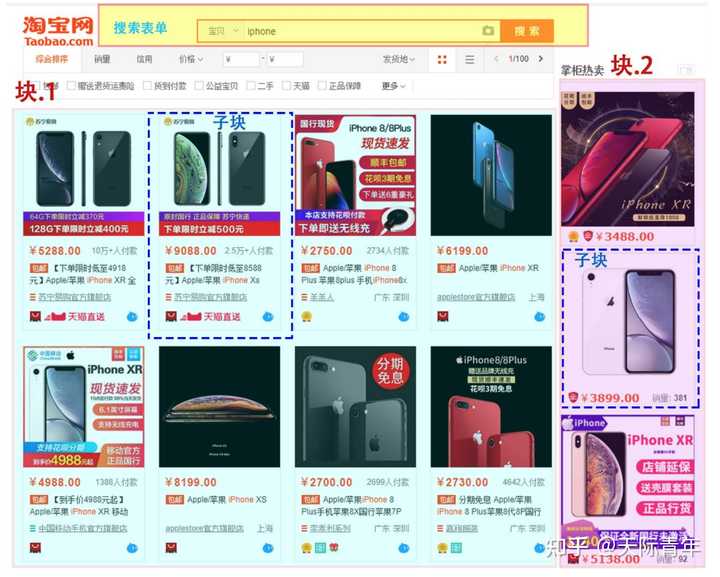
比如你看到这样的网站,信息很多,但你只想要一个excel表,告诉你地址,大小,总价和均价。


网址粘到我们低调的首页搜索框以后,选择你要哪一类数据,选一个,同类的就帮你选上了。
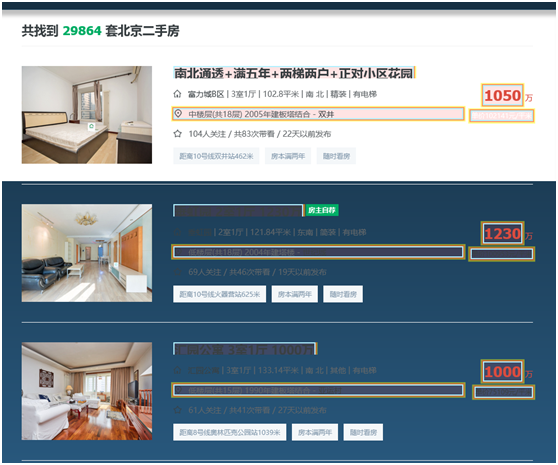

最后你会得到下面这样的列表:

注册好以后我们会给你生成一个控制台,然后选择你喜欢的格式输出就好了。
Excel也好,csv,json也罢,统统没问题。

(好多人点赞,我就把我的回答再好好的完善一下)
免费的爬虫软件,目前最好用的就是八爪鱼采集器。现在全球100万的用户都选择八爪鱼采集器,口碑就是最好的证明。
市场上那么多采集器可以选,为什么选择八爪鱼呢?选择一款好的免费采集工具到底最终要的衡量标准是什么呢?
1. 必须能采集任何网站,如果弄了半天你想采集的网站不支持那就悲剧了,八爪鱼是市面上采集网站覆盖最广的工具,支持任何网站的采集,而很多其他采集器只能覆盖大概60%的网站,大多数采集器对于需要登录,翻页,瀑布流、Ajax脚本异步加载数据等不能采集。
2. 学习上手容易,如果一个工具很牛逼,但是你不会用也是白扯,八爪鱼不需要你学习任何编程知识,也无需你懂网页通信原理,HTML,Javascript等技术背景,对于文科背景或者没有采集经验的小白是最佳选择,对比其他采集器,大多数需要你懂得技术背景,比如HTML,Javascript脚本分析,网络抓包,正则表达式匹配等,有些采集器还必须要写代码才能用。
3. 还需要操作简单,八爪鱼是国内唯一一家支持一键智能采集的爬虫工具,独创的智能模式,只需要用户输入要采集的网址(包含要采集的数据列表),点击一个智能采集按钮,数据就全自动的采集下来了,就像百度一样,看似一个简单的搜索框,其实背后的技术很复杂,当然对用户来讲,简单好用才重要,背后复杂高深的技术并不重要,所有优秀的产品一般都符合这个特征,就像苹果手机,正面只有一个按钮,但是背后却影藏了指纹解锁等技术。除了智能模式,八爪鱼还有自定义模式,通过点击鼠标选择要采集的数据,八爪鱼会自动生成可视化的采集流程度,非常容易理解和使用,到目前为止,八爪鱼也是全球范围内唯一具备可视化自定义流程的采集工具。
4. 当采集量很大,数据更新要求高的时候,必须能支持大规模采集,试想一下,如果你需要百度、58同城、微信、淘宝、京东、大众点评等平台时,上面的数据动辄几千万,每天更新几百万,如果你用一台电脑采集,这将是Mission impossible(碟中谍:不可能完成的任务),然而大多数的采集工具都是单机版工具,显然不行,八爪鱼在2014年第一个版本上线的时候,就率先在提出了“云采集”的概念,八爪鱼自建了一个由5000多台云服务器组成的庞大云采集集群,很多人可能没概念,5000台相当于早期雅虎搜索引擎的规模,这些服务器24*7的在为八爪鱼用户提供数据采集服务,单个用户在八爪鱼的采集量可以达到每天过千万条数据,在大数据的背景下,八爪鱼是业内唯一具备此能力的平台。
5. 可以应对常见防采集措施,可能你第一天接触采集的时候不需要了解防采集是什么,但是当你采集数据一段时间之后,相信你就会对此印象深刻,简单来讲,网站为了防止自己的数据被机器程序大规模采集,而采取了一系列技术手段来限制采集,这就是防采集,常见的防采集手段有登录、封IP,验证码、Ajax异步加载,瀑布流等,这些方法都非常有效,一般采集工具碰到这些的时候大多都歇菜了,如果你是一个自己写爬虫打码的工程师,相信你对此深有体会,八爪鱼致力于打造能突破一切防采集手段的工具,以上这些措施八爪鱼都可以搞定,当然也不止这些,八爪鱼甚至能像人浏览网页时一样,如果网页格式有变化,采用多种模板,或者弹出一个广告、登录、错误、验证码等页面,八爪鱼也能根据不同情况采用不同应对措施,包括自动识别和输入验证码等,这其中最难搞的一个就是IP限制,IP限制常用的解决方法有代理IP,VPN等,这些都要求你有大量的IP资源,然而IP资源是需要成本的,一个IP一个月的成本至少在50元以上,碰到主流的网站比如大众点评,阿里巴巴、天猫这些,如果要大规模采集,必须有成千上万的IP才行,八爪鱼的云采集集群IP不是固定的,而是像个水池一样,不断有新的IP加入,用过的IP退出,这样就有几十万上百万的IP可以使用,同时,一个采集任务还会被随机分配到很多台不同IP的云采集服务器上去,速度快效率高、还防采集。
6.其他,当然每个人采集需求都不一样,你可能还很看重其他的一些功能特点,比如是否有大量的学习教程资源、配置好的采集规则模板、活跃的交流社区、完善的客服支持、以及实现全自动采集同步数据的API接口等等,不用说、在这些方面八爪鱼都为大家考虑到了,我就不一一赘述。
7. 免费!免费!免费!最重要的事情说三遍,八爪鱼产品的设计有别于传统的采集工具或其他软件,传统的工具软件一般都是按照功能收费,个别有免费版的也是把核心功能都给阉割点了(话说不阉割咋收费呢, ),八爪鱼完全不同,免费版本具备所有功能,这点也是很多其他采集器没有的,到现在还有一些采集工具使用加密狗等方式来保护被阉割的功能,作为用户来讲我也是很无语,对于一般的需求而言,免费版本就满足所有需求了,当然,八爪鱼是个成功的商业产品,也设置了一些增值服务,如私有云等等,来满足高端付费企业用户的需要,用户都可以根据需要选择。
废话不多说,如果你想要的上面都有了,那没啥好犹豫的了,选择困难症、处女座也都该满意了吧,能动手的咱绝对不动口:
戳这里,免费下载八爪鱼
戳这里,八爪鱼学习教程资料
忘了啦,你还不知道八爪鱼长什么样,在这个看颜值的时代,必须爆图,有图有真相,我以采集京东商品数据为例,给大家截图看一下八爪鱼的采集界面:
1. 下载并安装八爪鱼客户端软件之后,打开,主界面长这样,简洁大方,有木有?:
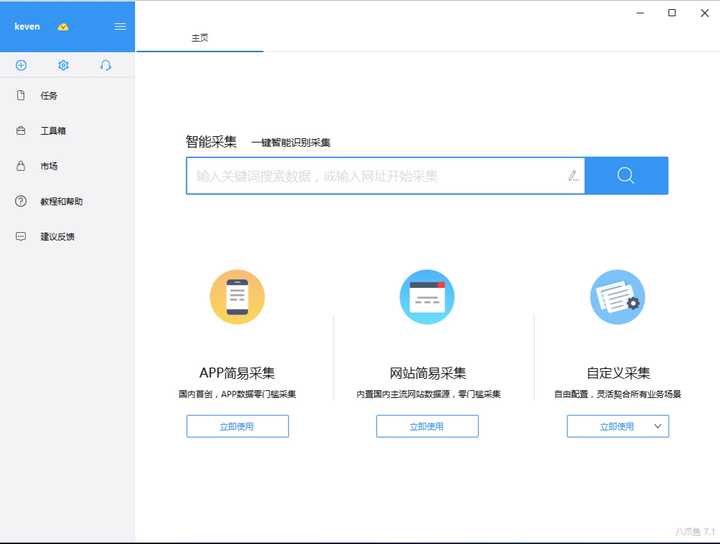

2. 看到APP采集了吧,(全球首创的技术,亮瞎我的钛合金**),看到内置国内主流网站采集了吧(零门槛我喜欢),喜欢就 点这里慢慢去了解,这里就跳过,重点讲一下主页中间的智能采集,在输入框中,输入我们要采集的网址:
https://list.jd.com/list.html?cat=9987,653,655
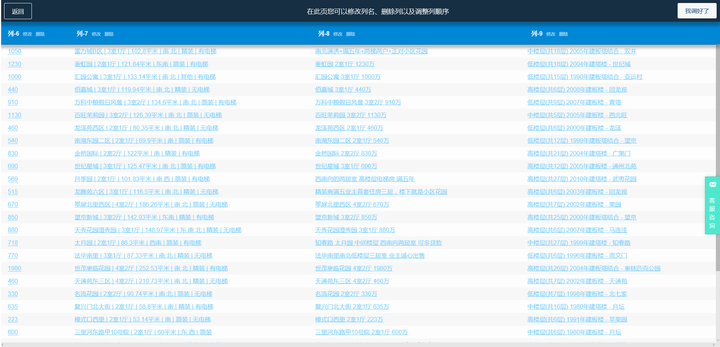
然后点击右边的放大镜按钮立即采集。稍等几秒钟,数据就出来了,我们再修改一下列名、删掉不需要的列(就跟excel一样),就得到了下面这个结果(4不4很简单 ):


当然啦,这只是用最简单的智能模式,更为强大的自定义模式和简易采集模式还是留给你自己去探索吧,用好自定义模式,你就无敌了,采遍互联网无敌手号称采花大盗的就是你了。
我知道有些人就是一目十行懒得看文字,那看图吧,功能和特色概览图:

部分典型用户:


另外,我列一个八爪鱼(公司名字叫深圳数阔信息技术有限公司)的资质给大家参考:
深圳数阔信息技术有限公司是领先的大数据工具与平台提供商。多年来致力于企业级数据整合、数据采集、清洗、分析及挖掘,在大数据领域拥有多项国际领先的知识产权和专利。旗下“八爪鱼”大数据采集平台、“数多多”数据资源交易平台处于行业领先地位,企业用户数超过30万。
点击下方链接 ,可免费体验数阔云听CEM系统:
公司创始人兼CEO刘宝强先生,毕业于国防科技大学,曾任职于morningstar(晨星资讯),负责morningstar(晨星资讯)全球金融大数据的收集和分析平台。曾在芝加哥(Morningstar全球总部)工作,在硅谷培训学习,对全球大数据产业发展有深入研究。
2015年1月获得国家重点软件企业大数据行业上市公司“拓尔思”500万天使投资
2015年6月获得双软认证
2015年9月在美国洛杉矶开设分公司Octoparse Data Inc,开展北美业务
2015年11月获得深圳市高新技术企业认证
2016年1月,《中国大数据企业排行榜》获五星评级
2016年5月,获得“云上贵州”大数据商业模式大赛“云路奖”
2016年6月,获得深圳市科创委专项资金扶持
2016年6月,获得知名投资机构“协同创新基金”Pre-A投资
2016年10月,获得阿里云“合作伙伴授权牌”银牌
2016年10月,获得“双创未来”2016年成都·深圳青年创客电视大赛一等奖
2016年10月,获得复星集团全球创新创业大赛第一名
2016年11月,获得世界互联网大会(乌镇)中国创客40强
2016年11月,获得大数据创新研究院“大数据创业企业100强”
2016年11月,获得国家高新企业认证
2017年1月,八爪鱼旗下自主研发的数据分析和可视化平台“微图”上线
2017年8月,获得全球潮人创新创业大赛第一名
老司机要开车了,上车链接在这里:
戳这里,免费下载八爪鱼
八爪鱼学习教程资料
2019年7月更新:
这个老问题,经久不衰,不断有人过来咨询和提问,我再补充一些新内容上来:
2018年12月,八爪鱼兄弟产品《云听CEM客户体验管理平台》获得中国大数据优秀解决方案TOP50,云听CEM使用AI技术为品牌企业提供深度消费者洞察和体验优化能力。
2019年5月,八爪鱼获得国家工信部2019大数据优秀产品认证
2019年5月,八爪鱼在贵阳大数据博览会发布的《大数据企业排行榜》再次获得数据采集类别第一名,这是八爪鱼连续第5次蝉联该领域第一。
2019年7月,八爪鱼推出教育公益计划,面向全球高校和教育领域的老师,同学们提供免费好用的数据采集工具,得到老师同学们广泛好评和支持。
 liubaoqiang@skieer.comhttps://www.zhihu.com/video/1135137256368066560
liubaoqiang@skieer.comhttps://www.zhihu.com/video/1135137256368066560



如果我写了一天的内容对你有用,欢迎点个赞哈,O(∩_∩)O谢谢

我们发现,写爬虫是一件炫酷的事情,但即使是这样,学习爬虫仍然有一定的技术门槛。
当前的主流爬虫手段是用Python编程,Python的强大毋庸置疑,但初学者学习Python还是需要一两个月时间的。
有没有一些更简单的爬取数据方法呢?答案是有的。
一些可视化的爬虫工具通过策略来爬取特定的数据, 虽然没有自己写爬虫操作精准,但是学习成本低很多,下面就来介绍几款可视化的爬虫工具。
01 国内工具
Microsoft Excel
首先教大家一个用Excel爬取数据的方法,这里用的Microsoft Excel 2013版本,下面手把手开始教学~
(1)新建Excel,打开它,如下图所示


(2)点击“数据”——“自网站”


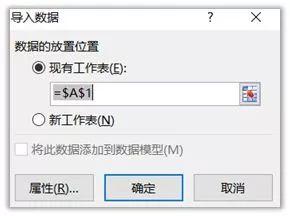
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击转到,再导入


选择导入位置,确定;
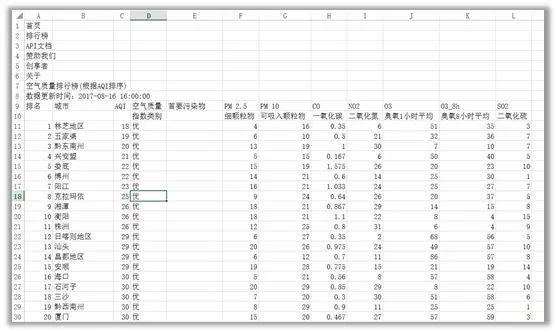
(4)结果如下图所示,怎么样,是不是很赞?

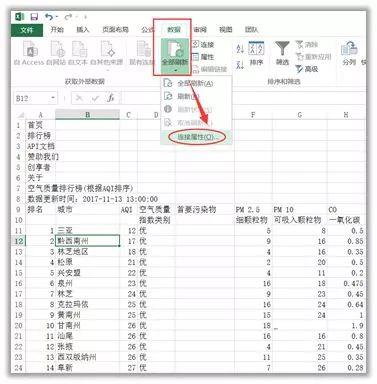
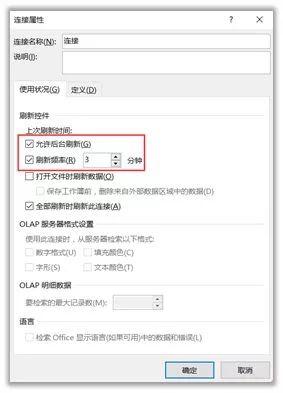
(5)如果要实时更新数据,可以在“数据”——“全部更新”——“连接属性”中进行设置,输入更新频率即可
八爪鱼 https://www.bazhuayu.com/
一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。

一款适合小白用户尝试的采集软件,云功能强大,当然爬虫老手也能开拓它的高级功能。
火车头 http://www.locoy.com/
火车头是一款互联网数据抓取、处理、分析,挖掘软件,采集功能完善,不限网页与内容,任意文件格式都可下载,号称能采集99%的网页。


软件定位比较专业而且精准化,使用者需要有基本的HTML基础,能看得懂网页源码,网页结构,但软件提供相应教程,新手也能够学习上手。
集搜客
http://www.gooseeker.com/index.html
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。


操作较简单,适用于初级用户,功能方面没有太大的特色,后续付费要求比较多。
神箭手云爬虫 https://www.shenjian.io
一款新颖的云端在线智能爬虫/采集器,基于神箭手分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据。

类似一个爬虫系统框架,具体采集还需用户自写爬虫,需要代码基础。
狂人采集器 http://www.kuangren.cc/
一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,分论坛采集器、CMS采集器和博客采集器三类。


专注论坛、博客文本内容的抓取,对于全网数据的采集通用性不高。
02 国外工具
Google Sheet
http://google.cn/sheets/about/
使用Google Sheet爬取数据前,要保证三点:使用Chrome浏览器、拥有Google账号、电脑已翻墙。如果这三个条件具备了的话,下面我们就开始吧~
(1)打开Google Sheet网站:

(2)在首页上点击“转到Google表格”,然后登录自己的账号,可以看到如下界面,再点击“+”创建新的表格

新建的表格如下:


(3)打开要爬取的目标网站,一个全国实时空气质量网站 http://pm25.in/rank,目标网站上的表格结构如下图所示:
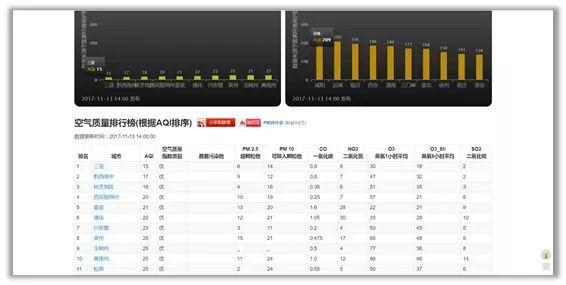

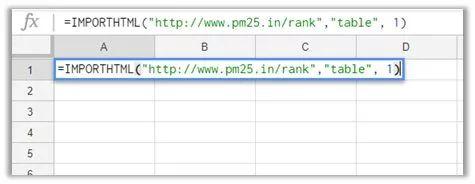
(4)回到Google sheet页面,使用函数=IMPORTHTML(网址, 查询, 索引),“网址”就是要爬取数据的目标网站,“查询”中输入“list”或“table”,这个取决于数据的具体结构类型,“索引”填阿拉伯数字,从1开始,对应着网站中定义的哪一份表格或列表;
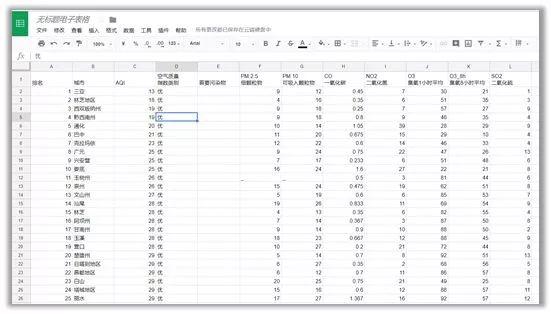
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入函数=IMPORTHTML(" http://pm25.in/rank","table",1),回车后就爬得数据啦~


(5)将爬取好的表格存到本地

you-get
这是一个程序员基于python 3开发的项目,已经在github上面开源,支持64个网站,包括优酷、土豆、爱奇艺、b站、酷狗音乐、虾米……总之你能想到的网站都有! 还有一个黑科技的地方,即使是名单上没有的网站,当你输入链接,程序也会猜测你想要下载什么,然后帮你下载。
当然you-get要在python3环境下进行安装,用pip安装好后,在终端输入“you get+你想下载资源的链接”就可以等着收藏资源了。
这里给一个you-get的中文使用说明,按照说明上写的按步骤操作就可以啦。
http://Import.io是一个基于Web的网页数据采集平台,用户无需编写代码点选即可生成一个提取器。相比国内大多采集软件, http://Import.io较为智能,能够匹配并生成同类元素列表,用户输入网址也可一键采集数据。


http://Import.io智能发展,采集简便,但对于一些复杂的网页结构处理能力较为薄弱。
Octoparse
https://www.octoparse.com/
Octoparse是八爪鱼的海外版,采集页面设计简单友好,完全可视化操作,适用于新手用户。
Octoparse功能完善,价格合理,能够应用于复杂网页结构,如果你想无需翻墙直采亚马逊、Facebook、Twitter等平台,Octoparse是一种选择。
visual web ripper
http://visualwebripper.com/
Visual Web Ripper是一个自动化的Web抓取工具,支持各种功能。

它适用于某些高级且采集难度较大的网页结构,用户需具备较强的编程技能。
content Grabber
http://www.contentgrabber.com/
Content Grabber是功能最强大的Web抓取工具之一。它更适合具有高级编程技能的人群,提供了许多强大的脚本编辑,调试界面。允许用户编写正则表达式,而不是使用内置的工具。
Content Grabber网页适用性强,功能强大,不完全为用户提供基础功能,适合具有高级编程技能的人群。
Mozenda
https://mozenda.updatestar.com/
Mozenda是一个基于云服务的数据采集软件,为用户提供许多实用性功能包括数据云端储备功能。

适合拥有基础爬虫经验的人群。
还有更多大数据、数据分析、爬虫等学习资料分享,关注公众号【DataCastle数据城堡】领取哦~

注意,不同于其他号称“免费”的软件,EasySpider这个软件是真的免费,真的免费,真的免费!!!不需要注册,没有任何收费接口和页面,所有信息完全存在用户本地,代码开源!!!
V0.3.0版本新增的功能,包括下载图片,元素截图,执行任意JS指令和系统命令,通过JS代码进行条件判断,OCR识别等等功能,想要的功能应有尽有,而且这些功能完全免费!!!
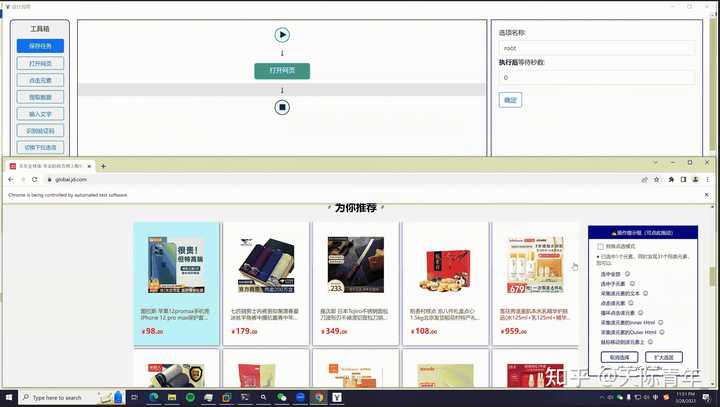
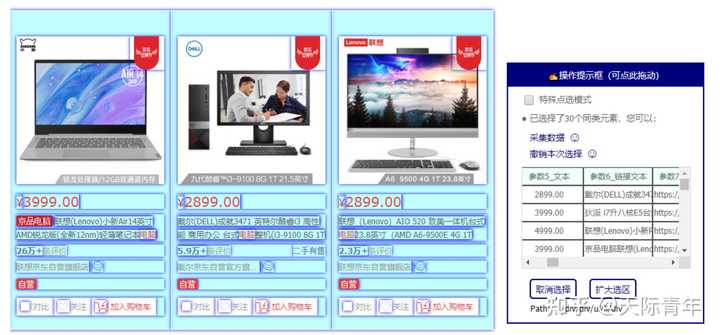
软件介绍
EasySpider是一款完全免费和开源的可视化爬虫软件,此软件可以让大家使用图形化界面,无代码可视化的设计和执行爬虫任务。只需要在网页上选择自己想要爬的内容并根据提示框操作即可完成爬虫设计和执行。同时软件还可以直接在命令行中通过传参的方式执行,从而可以很方便的嵌入到其他系统中。
以下是示例界面:



相关链接
代码仓库
Github仓库地址,欢迎大家Star:
下载 EasySpider
进入Releases Page: https://github.com/NaiboWang/EasySpider/releases 下载最新版本。
视频教程
https://www.bilibili.com/video/BV1th411A7ey/
文档
教程文档: https://github.com/NaiboWang/EasySpider/wiki,有英文可以暂时翻译一下,或看作者的硕士毕业论文: https://github.com/NaiboWang/EasySpider/blob/master/Docs/面向WEB应用的智能化服务封装系统设计与实现.pdf(主要看第三章和第五章)。
为什么要用EasySpider
相比其他可视化爬虫软件,EasySpider有以下优势:
1. 代码开源,因此可以进行二次开发。
2. 完全免费,不同于八爪鱼等软件的“免费”,EasySpider是一个无需登录,无限多开,无限机器部署的软件,不需要向作者本人支付一分钱。(当然,EasySpider受到专利保护,因此如果要商用,还请联系浙江大学天道专利事务所)。相比之下,其他软件的免费有诸多限制,具体可以看他们的价格详情页。
3. 安全,所有信息完全保存在用户本地,包括任务和采集的数据,不用担心数据泄露问题。
4. 跨平台:同时支持Windows,Linux和MacOS。
5. 速度快,通常一个爬虫任务只需要2-5分钟即可设计完成,采集速度也快,通常取决于具体机器环境。
6. 更加灵活,保存的浏览器配置信息更多,最重要的是可扩展,自由的安装各种插件,比如验证码识别插件。
7. 可以直接以命令行的方式执行,无限部署在任何想要部署的机器中。
8. 可以在任务流程中执行自定义的指令,包括JavaScript指令以及系统级别指令,这个是目前所有的可视化爬虫软件都做不到或者不愿意做的事情。
9. V0.3.0版本新增的功能,包括元素截图,执行任意JS指令和系统命令,OCR识别等等功能,想要的功能应有尽有,而且这些功能完全免费!!!


从需求导向来说,爬虫算是一项基本的需求,我们经常需要去爬一些网上的信息,比如对于科研工作者,爬取维基百科语料库进行训练是做NLP的同学经常做的事情;做社交网络分析的同学经常需要爬取Twitter和微博的信息;做推荐系统的同学会去爬购物网站的信息等等。市面上爬虫需求很多,这里就不在赘述了。有了EasySpider,不管大家之前会不会写爬虫,现在都可以不需要费心费力的写代码了。
相关荣誉和出版物
1、 作者本人通过此软件完成了浙江大学硕士论文并取得了硕士学位。
2、 获得了中国国家发明专利授权,作者是第一发明人。
3、 被CCF A顶级会议WWW 2023接收: https://dl.acm.org/doi/abs/10.1145/3543873.3587345
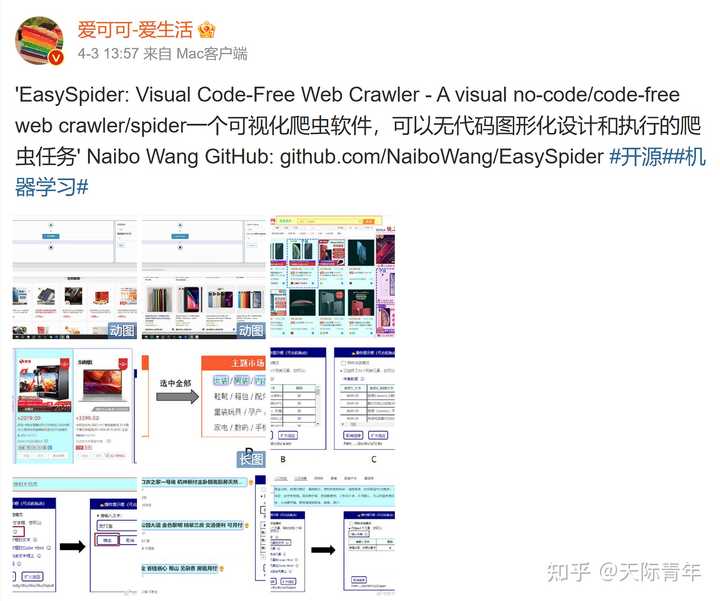
4、 被微博81.6万粉丝互联网大V“爱可可-爱生活”转发和宣传: https://s.weibo.com/weibo?q=easyspider

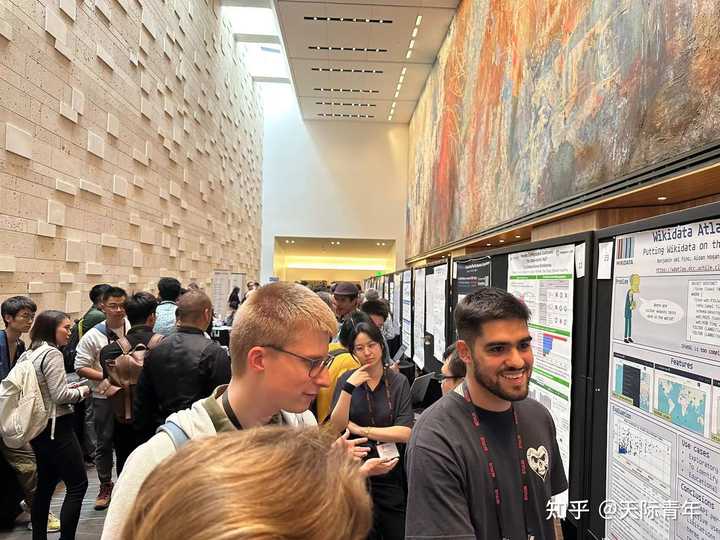
楼主刚从美国参加WWW 2023回来,当时很多人对该软件感兴趣,下面是现场海报:



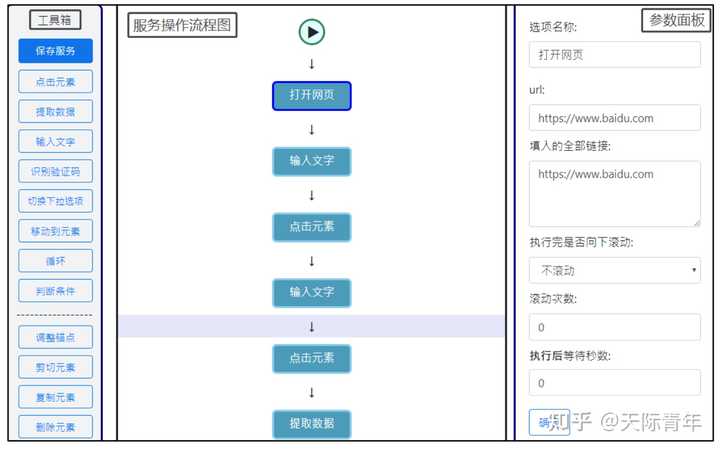
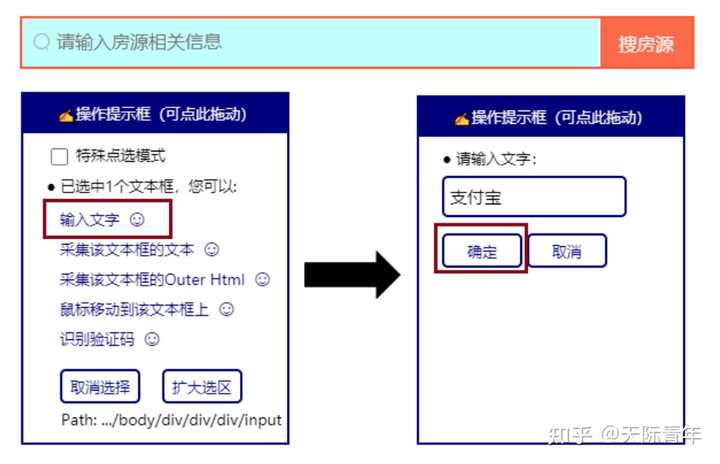
软件相关截图
这些图片来自我的硕士论文,这里只放图,具体这些图是做什么的请大家去看我的硕士论文,因为太长了:
https://github.com/NaiboWang/EasySpider/blob/master/Docs/面向WEB应用的智能化服务封装系统设计与实现.pdf
















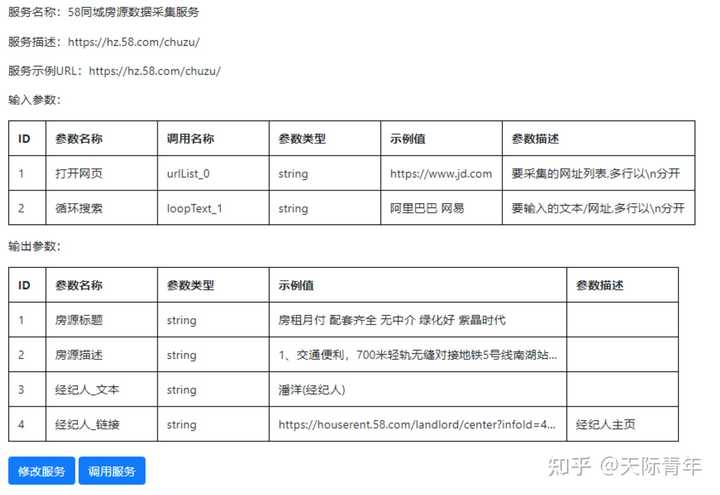

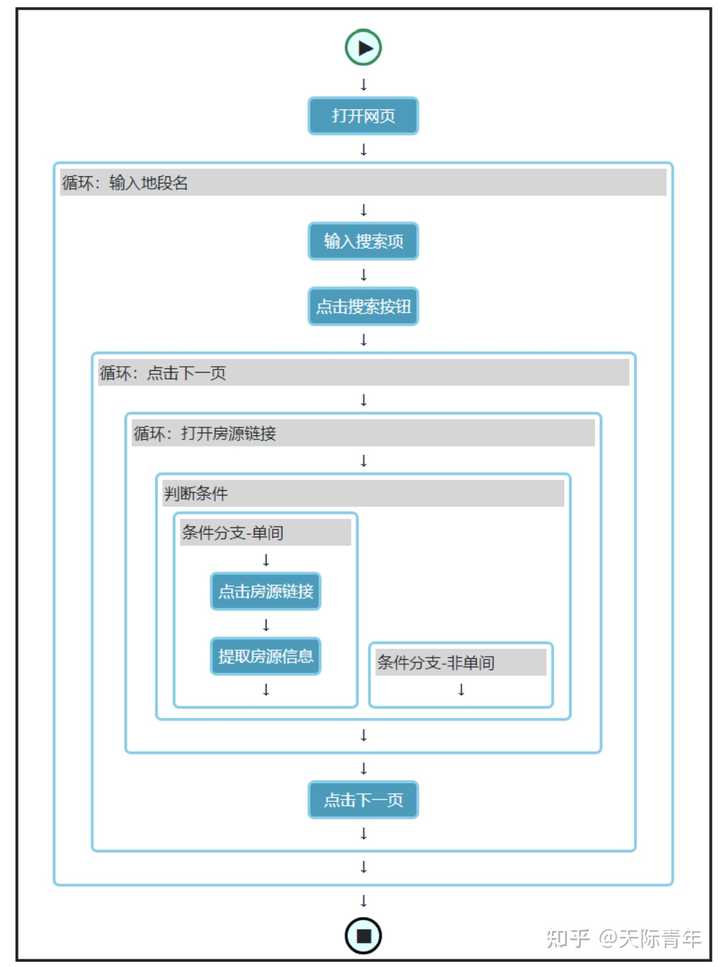

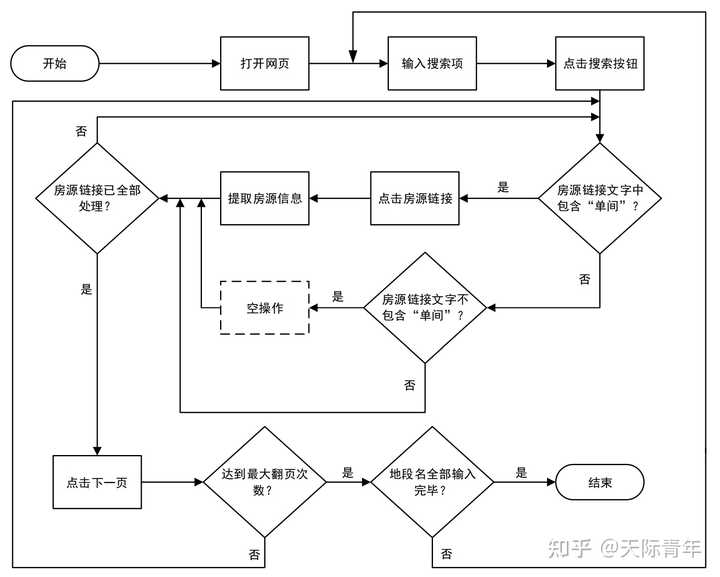





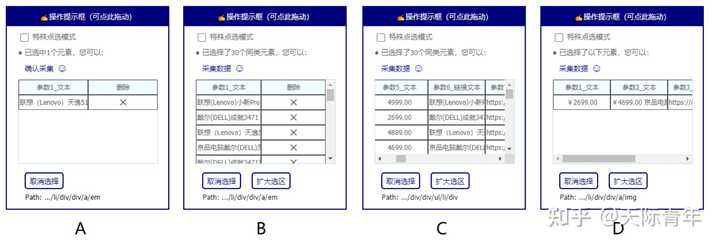

技术交流
由于EasySpider所有的算法设计,代码实现以及文档编写都是我一个人完成的,所以项目肯定不如一个团队一起写那么完善,而且很多功能我想开发也是心有余而力不足,所以肯定有很多可以改进的地方。由于代码全部公开,所以大家可以自行fork之后进行修改和添加新功能,也欢迎大家提PR使得这个软件的功能更加完善,共同构建一个美好的开源社区。 对于软件中涉及到的算法细节,大家可以看楼主的硕士毕业论文,里面写的很详细: https://github.com/NaiboWang/EasySpider/blob/master/Docs/面向WEB应用的智能化服务封装系统设计与实现.pdf 对于软件开发使用到的具体技术,如chrome扩展开发,websocket的使用,ElectronJS跨平台框架等等,大家可以在下载代码之后去研究下我的写法,我相信我的代码写法绝不是最好的,甚至当时由于想赶紧毕业所以只是想写一个能用的demo出来所以可以说有些粗糙,比如耦合性太强,不够模块化等等,因此可改进空间还有很多,欢迎大家提出意见和建议。 对于初学CS的学弟学妹来说,这个项目也算是不错的样例,因为从开发角度来说,这个项目包含了前端开发,后台开发,数据库操作,浏览器扩展开发等模块;从算法角度来说,这个项目包含了如深度优先,广度优先,数据结构,图,编译原理,递归等等算法技巧。大家如果想学习,也许可以从这个项目源码里学到一些知识。 最后,真心希望软件可以帮到大家!

利益相关,这里我推荐我们家的八爪鱼采集器
针对小白用户,上手特别简单,简单的网页数据爬取几分钟就能搞定
支持多种数据格式导出,比如Excel,mysql等等,与数据分析无缝连接
不知道题主需要爬取那个网站数据,我给题主简单介绍一下软件吧:
1、模板采集(0基础,简单三步获取数据,纯鼠标和输入文字操作,小白友好)
打开运行在PC端的八爪鱼客户端,直接搜索网站,看看有没有包含您想要采集的目标网站。万一包含,只需要动动鼠标输入文字,采就完事了。
目标采集模板数也是非常多的,基本上主流网站都有包含,看看下面的图片就知道了。


以京东商品采集给大家详细演示采集过程:
 简单3步,日采集海量京东数据https://www.zhihu.com/video/1242048148585533440
简单3步,日采集海量京东数据https://www.zhihu.com/video/1242048148585533440具体详细使用教程: 使用模板采集数据
2、自定义采集模式(内置智能模式,自动识别网页内容数据,自由度高,轻松采数据)
如果【模板采集】里没有想要采集的网站,那就自己来,八爪鱼内置智能模式,可以自动识别网页内容进行采集。
以今日头条新闻采集给大家演示操作流程:
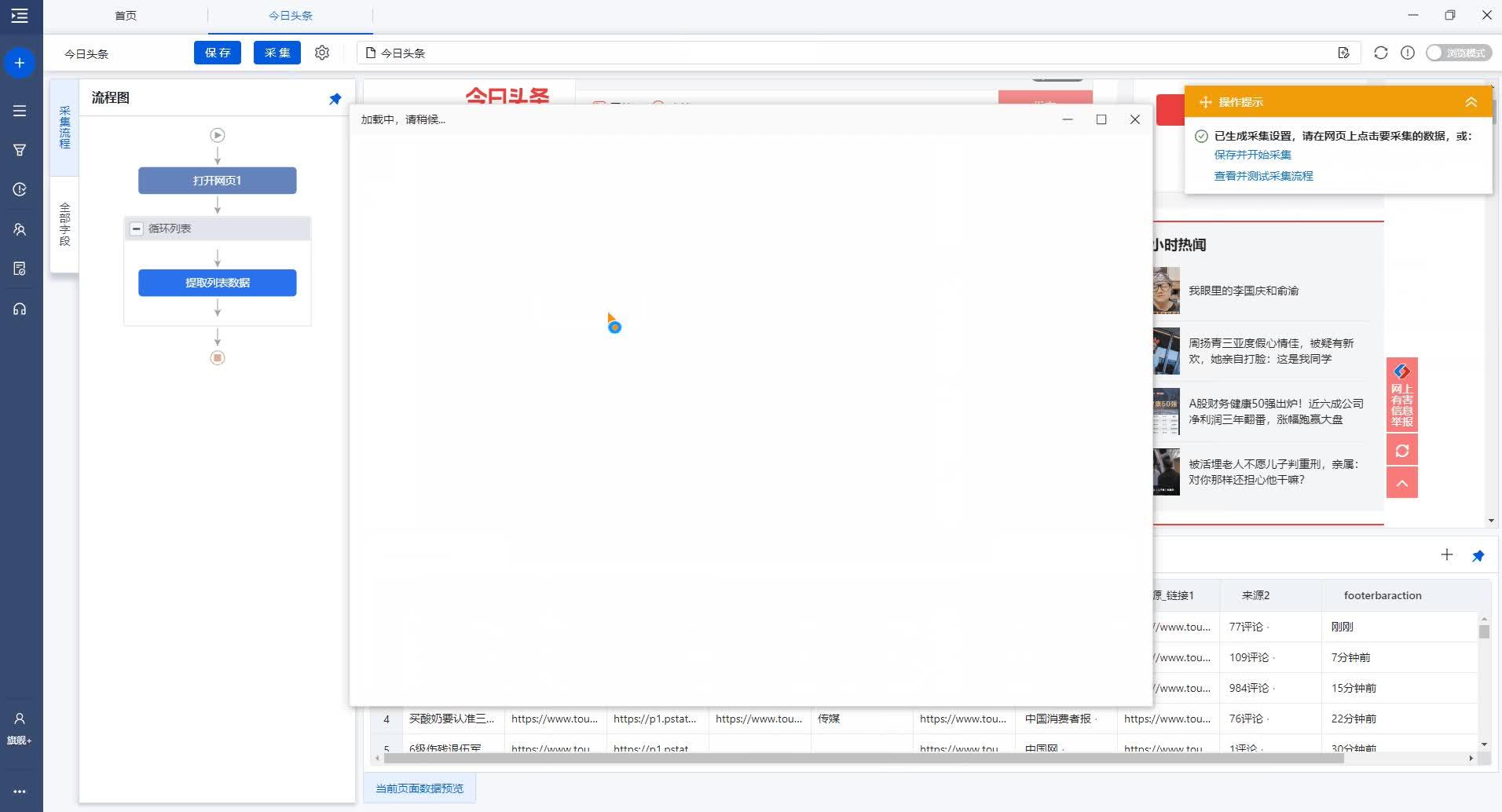 今日头条新闻一键智能识别采集https://www.zhihu.com/video/1242049028604755968
今日头条新闻一键智能识别采集https://www.zhihu.com/video/1242049028604755968具体详细使用教程: 自定义配置采集数据(含智能识别)
如果您对用八爪鱼采集网页数据有兴趣,可以用电脑下载客户端试试。
下载地址:
使用过程中遇到任何问题,都可以来问小八哟~

市面上有两种免费的网络爬虫软件:
第一种:免费使用,免费采集数据,但是不是免费导出采集结果的(包括限制导出格式,例如只能导出txt格式,或者导出数据要积分);
第二种:免费使用,免费采集数据,免费导出采集结果的;
利益相关:我们后羿采集器是第二种免费的爬虫软件。

使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,可以实现不写代码,指哪爬哪的目标。 当然你得爬墙去chrome一趟:
https://pic1.zhimg.com/v2-80728428c8af4c1f360d70c3ddf32820_b.png
Web Scraper 的学习内容虽然简单,但你还得学点东西。比起写代码,已经强很多了。
- 官网中的视频教程 http://webscraper.io/tutorials
- 知乎 @陈大欣 的回答 中写了详细的步骤,并录制了视频教程。
- 视频教程(1): http://www.bilibili.com/video/av9664397/
- 视频教程(2): http://www.bilibili.com/video/av9708200/
- 这个问题来源 零基础如何学爬虫技术? @陈大欣 在文章中把 Excel 爬虫,web scraper,代码爬虫做了比较分析
https://pic1.zhimg.com/v2-e71376447a0299cbb2bc2ebdfdf41c60.png
关注这个公众号的都是奇才。

之前同学有用过带界面的程序,貌似是专门爬某门户网站新闻用的。但是没用多久就跟我说想爬淘宝的商品信息,怎么办,我告诉他自己写一个,然后就没有然后了。爬虫这种东西针对性很强,每个网站的就够,数据获取方式,数据结构千变万化,所以自己写个没什么坏处(如果你是个程序员或者经常从事相关的数据搜集工作)。
可以从java入手,很容易找到中文教程。
httpClient+jsoup
先试着爬一个不用登陆,安全级别低的网站,例如成人网站(现在电脑里还有某成人网站所有电影的磁力连接。。)
然后爬一个需要登陆的网站,你会就会去研究模拟登陆,http协议,cookie这些东西
然后再爬一个难度较高的网站,新浪微博啦,豆瓣啦,你就会研究识别验证码,反爬虫机制之类的东西
如果你想把爬下来的东西做成像百度,谷歌一样的搜索引擎,可以研究lucene,solr这些东西
如果你想提高你的爬虫效率,你就会研究多线程,分布式这些东西,搞个mongoDB玩玩也是不错的
这些都是我今年年初做毕业论文的时候学到的,总之东西都不难,难的是真正动手去做,越做越有自信。

推荐谷歌插件 webscraper,可以方便的抓取网页上的内容:文字、链接、图片、表格等,而无需写一行代码。
优势:
- 免费
- 不受操作系统限制,只要安装Chrome浏览器即可运行
- 操作简单,易上手。(很多没有技术背景的同学,都可以快速学会)
- 功能强大:不仅可以抓静态网页,对于js动态加载的数据,也很容易抓取
根据已经测试的经历,下列类型网站均可抓取——
- 58同城、大众点评、美团、链家等
- 微信公众号、简书、知乎、博客等
- 淘宝、阿里巴巴、网易严选等
可以在浏览器查看到的数据,99%均可抓取。
1、下载安装
查看视频按照操作即可
操作也非常简单:
可以查看下面几篇文章:

老王卖瓜,不夸是傻瓜。哈哈哈,当然我这是也是真的好瓜
推荐下爬山虎采集器 ,大概说说它的特点吧
- 一键提取数据,简单易学,通过可视化界面,鼠标点击即可抓取数据
- 快速高效,内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
- 适用各种网站,能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
相比于同类的采集软件,它在用户体验、抓取效率上做了一个平衡。
希望可以帮助你。

这是我在知乎里面看到最碉的excel应用,推荐给你。
零基础如何学爬虫技术? - 知乎
点进去你就可以看到《 8次鼠标点击,教会你用excel做网页数据爬虫 》
当然如果你不满足这个,你可以试试神箭手云爬虫
神箭手云爬虫-云端在线爬虫开发平台-神箭手云爬虫
这个平台是我目前用过的入门比较简单,可定制很强的云爬虫。
看一下开发文档,自己写一个爬虫不难。
比如我自己都写了好几个
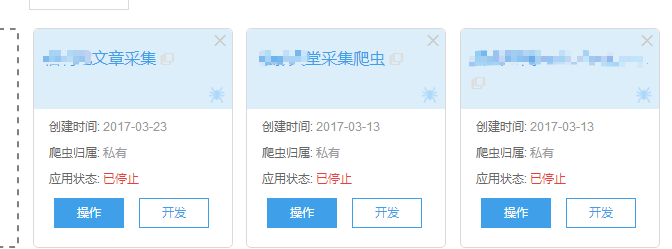

这是爬虫的代码,这个爬虫主要是用js来写的,图片中街区的部分主要就是爬虫要爬取的数据判断。他的判断这里主要是用的css来爬取,高级一点的你还可以用正则,不过不重要,重要的是能爬到我们想要的数据。


这个是爬取结果,只是我自己写的,所以主要字段是这个,你需要爬金融数据什么的,就需要你自己去写具体要取什么数据了。
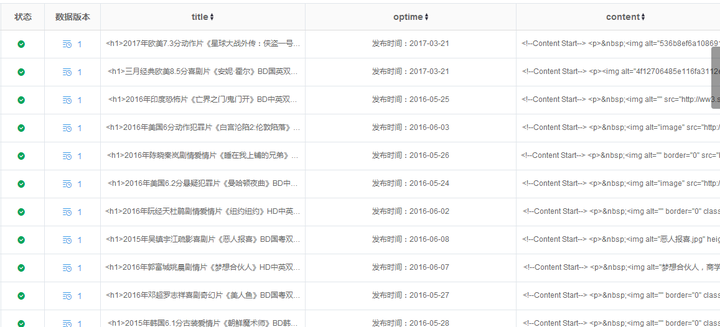

爬取的数据支持直接导出到excel之类的,也方便你分析。
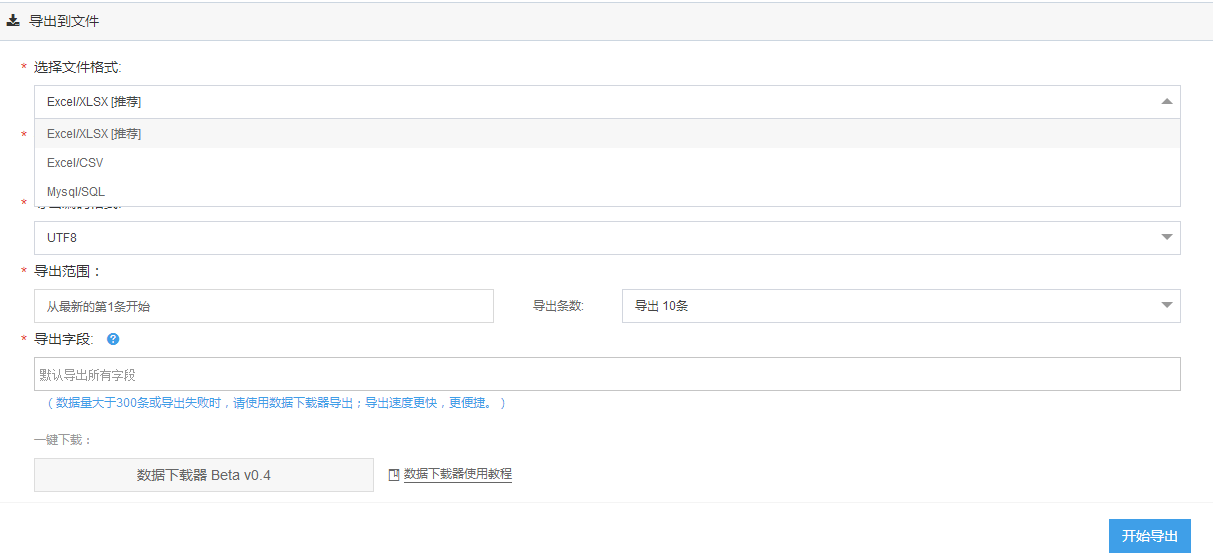

还有一个很重要的点,就是这个平台免费啊,是免费的云爬虫,也就是说你写好了爬虫开始运行后,你就可以关掉电脑,第二天起来再登陆进去看数据了。很多软件都是需要你开着电脑去爬的。
看看ForeSpider,现在使用率比较高的软件,我身边的搞数据的朋友都是用的他们,跟别的软件相比,采集速度快,采到的数据还很全面,你可以下个免费版感受一下。

网络爬虫是个“古老”的领域,自互联网诞生就有需求去爬其内容,网络爬虫同时又是一个年轻的领域,互联网技术日新月异的发展,网络爬虫必须跟着发展。
时至今日,网络爬虫必须很好地解决javascript动态内容的抓取、html5的支持(甚至抓取html5的效果和图表)、异步加载的内容等等,另外,随着大家越来越看重数据价值,还要有很好的反爬机制,比如,不要在云服务器上用固定IP做爬虫,而是分散式的协同化方案。
从行业发展来看,产品越来越集中,免费是主流的,甚至开源。最近我对这个领域做了总结和重新思考,将网络爬虫进一步细分成即时网络爬虫和收割式网络爬虫,即时网络爬虫采用Python开源的发布模式,方便大家嵌入到自己的数据处理系统中,可以关注我新建的知乎专栏。

八爪鱼,让数据触不可及,没钱只可仰望

不需要写一行代码就可以爬取网站数据,推荐一个 Web Scraper (谷歌浏览器插件),小白爬虫利器,5 分钟配置一个爬虫。
具体教程可参考我的这一个回答,列举的例子是爬取豆瓣小组的数据: